
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 공빅
- 공공빅데이터청년인턴
- Keras
- Kaggle
- DL
- SQL
- machinelearning
- datascience
- 2023공공빅데이터청년인재양성후기
- textmining
- DeepLearning
- decisiontree
- 빅데이터
- data
- NLP
- 오버샘플링
- ADsP3과목
- 데이터분석
- k-means
- ML
- 분석변수처리
- 데이터전처리
- 2023공빅데
- ADSP
- 텍스트마이닝
- 2023공공빅데이터청년인재양성
- 공공빅데이터청년인재양성
- 머신러닝
- 공빅데
- 클러스터링
- Today
- Total
愛林
SQL을 이용한 정형 데이터 다루기 - SQL기본이해, DDL 본문
RDBMS와 SQL

RDBMS 는 앞에서 배웠듯이 관계형 데이터베이스이다.
관계형 테이블 용어를 알고 들어가야 한다.
■ 관계형 테이블 용어
- Row(행, tuple) : 2차원 구조를 가진 테이블에서 가로형.
- Column (열, attribute) : 2차원 구조를 가진 테이블에서 세로형.
- Field : 칼럼과 행이 겹치는 하나의 공간
- Primary Key(PK) : 유일하게 테이블의 각행을 식별한다. Not null, unique 조건을 만족
- Foreign Key(FK) : 열과 참조된 열 사이의 외래키 관계를 적용하고 설정. 다른 열의 PK 가 들어온다.
SQL (Structured Query Language)
SQL 은 구조화된 쿼리 언어를 말한다.
초기에는 SEQUEL(Structured English Query Language, 구조 영어 질의어) 라는 이름으로 시작했지만.
계속된 개정으로 현재는 SQL 로 불리우고 있다.
SQL 의 종류로는 데이터 정의어(DDL), 데이터 조작어(DML), 데이어 제이어(DCL) 가 있다.
1) 데이터 정의어(DDL, Data Definition Language)
데이터와 데이터 간의 관계 정의를 위한 언어로, 데이터베이스 내에서 테이블과 같은 데이터 구조 또는 객체를 생성, 변경, 삭제하는 데에 사용된다. (CREATE(생성), ALTER(변경), DROP(삭제), RENAME(재정의))
데이터베이스 스키마(데이터의 데이터. 테이블 상위 항목) 를 컴퓨터가 이해할 수 있도록 기술하는 데에 사용된다.
2) 데이터 조작어(DML, Data Manipulation Language)
데이터베이스 사용자 또는 응용 프로그램의 데이터 검색, 등록, 삭제, 갱신 등의 처리를 위한 언어이다.
(SELECT(조회), FROM ,WHERE, INSERT(객체에 입력), UPDATE(데이터수정), DELETE(객체데이터삭제))
데이터베이스 객체 안의 데이터를 입력,수정,삭제,조회 할 수 있으므로 핵심적인 기능이다.
3) 데이터 제이어(DCL, Data Control Language)
데이터베이스에서 데이터에 대한 접근을 제어하기 위한 언어로 데이터 보안, 무결성, 병행 수행 제어에 사용된다.
(GRANT(권한부여), REVOKE(권한취소), COMMIT, ROLLBACK,DENY(권한거부,우선된다))
데이터베이스를 공동으로 사용하기 위해 데이터 제어를 정의하고 기술하기 위해 사용한다.
데이터베이스 객체(Objects) (데이터베이스에 저장된 정보) 에는 테이블(기본저장단위), 뷰(가상테이블), 시퀀스(unique한값), 인덱스(원하는정보를 빠르게찾을 수 있게 함), 동의어(별칭, 긴 이름을 짧게 만들기)가 있다.
TCL(Transaction Control Language)
TCL 을 배우기 전, 먼저 트랜잭션(Transaction) 을 알고 들어가야 한다.
■ 트랜잭션(Transaction) 의 정의
데이터베이스의 논리적 연산 단위로 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 의미한다.
분할할 수 없는 최소 단위 인 것이 중요하다.
하나의 트랜잭션에는 하나 이상의 SQL 문장이포함된다.
DBMS 는 트랜잭션을 근거로 데이터의 일관성을 보증해준다.
-> 전부 적용하거나, 전부 취소하는 ALL OR NOTHING (일관성)
하나의 작업단위라고 보면 된다.
Ex:) 계좌이체라는 작업단위는 두 개의 스텝이 모두 성공적으로 완료되었을 때 종료된다.
둘 중 하나라도 실패할 경우 계좌이체는 원래 금액을 유지해야 한다. (돈이 빠져나가기만 하고 입금이 되지 않으면 안됨)
계좌이체가 하나의 트랜잭션인 것임.
■ 트랜잭션의 ACID 특징
- Atomicity (원자성) : 연산 전체가 성공적으로 처리되거나 한개라도 실패할 경우 전체가 취소되는 무결성.
All or Nothing -> commit / Rollback 연산을 관리한다.
- Consistency (일관성) : 트랜잭션이 실행을 성공적으로 완료하면 언제나모순 없이 일관성 있는 데이터베이스 상태를 보존한다. 순서대로 일어나는 것을 말한다. (출금이 되고 나서 입금이 되는 것)
- Isolation (고립성) : 트랜잭션이실행 중에 생성하는 연산의 중간 결과를 다른 트랜잭션이 접근할 수 없다.
(입금이 되고 있는 상태에 출금 트랜잭션이 바로 일어날 수 없다.)
- Durability (영속성) : 성공이 완료된 트랜잭션의 결과는 영구적으로 데이터베이스에 저장된다.
트랜잭션이 종료될 시에는 Commit(완료) 연산이나 RollBack(복귀) 연산이 일어난다.
트랜잭션을 제어하는 SQL 은
COMMIT = 완료. 변경된 데이터를 데이터베이스에 영구적으로 반영
ROLLBACK = 복귀, 변경사항을 취소
SAVEPOINT = 데이터 변경을 사전에 지정한 저장점까지만 롤백
이 있다.
commit 이나 rollback 연산을 사용함으로서 논리적으로 연관된 작업을 그룹핑하여 처리가 가능하고,
한 번 완료되면 영구적으로 변경할수 없는 데이터베이스의 특징을 고려하여 변경사항을 한 번 더 확인하게
해준다. 데이터의 무결성(ALL OR NOTHING) 도 보장된다.
테이블 생성 / 수정 / 삭제 (DDL)
CREATE TABLE 문을 사용해서 데이터베이스에 새로운 테이블을 생성한다.
CREATE TABLE [스키마.]테이블
(
컬럼1 데이터타입 [NOT NULL] [WITH DEFAULT [값]]
, ...
, 컬럼2 데이터타입 [NOT NULL] [WITH DEFAULT[값]]
[, PRIMARY KEY 절, ...]
[, UNIQUE KEY 절, ...]
[, FOREIGN KEY 절, ...]
[, CHECK 절, ...]
)
...
[WITH RESTRICT ON DROP] # 비정상 시에 DROP 해주는 것TABLE 이름을 명명하기 전에, 명명법을 살펴보고 가자.
- 테이블 명은 객체를 의미할 수 있는 적절한 이름을 사용한다 (가능한 단수형)
- 테이블명은 다른 테이블의이름과 중복되지 않아야 한다. (동일 사용자가 소유한 다른 object 이름과 중복 금지)
- 한 테이블 내에서는 컬럼명이 중복되게 할 수 없다. (다른 테이블은 가능)
- 테이블명과 컬럼명은 반드시 문자로 시작한다. (숫자 절대절대 금지) 제발 기억해줘
- 1 - 30자 문자 길이
- 반드시 A-Z, a-z, 0-9, _, $, # 문자만 허용
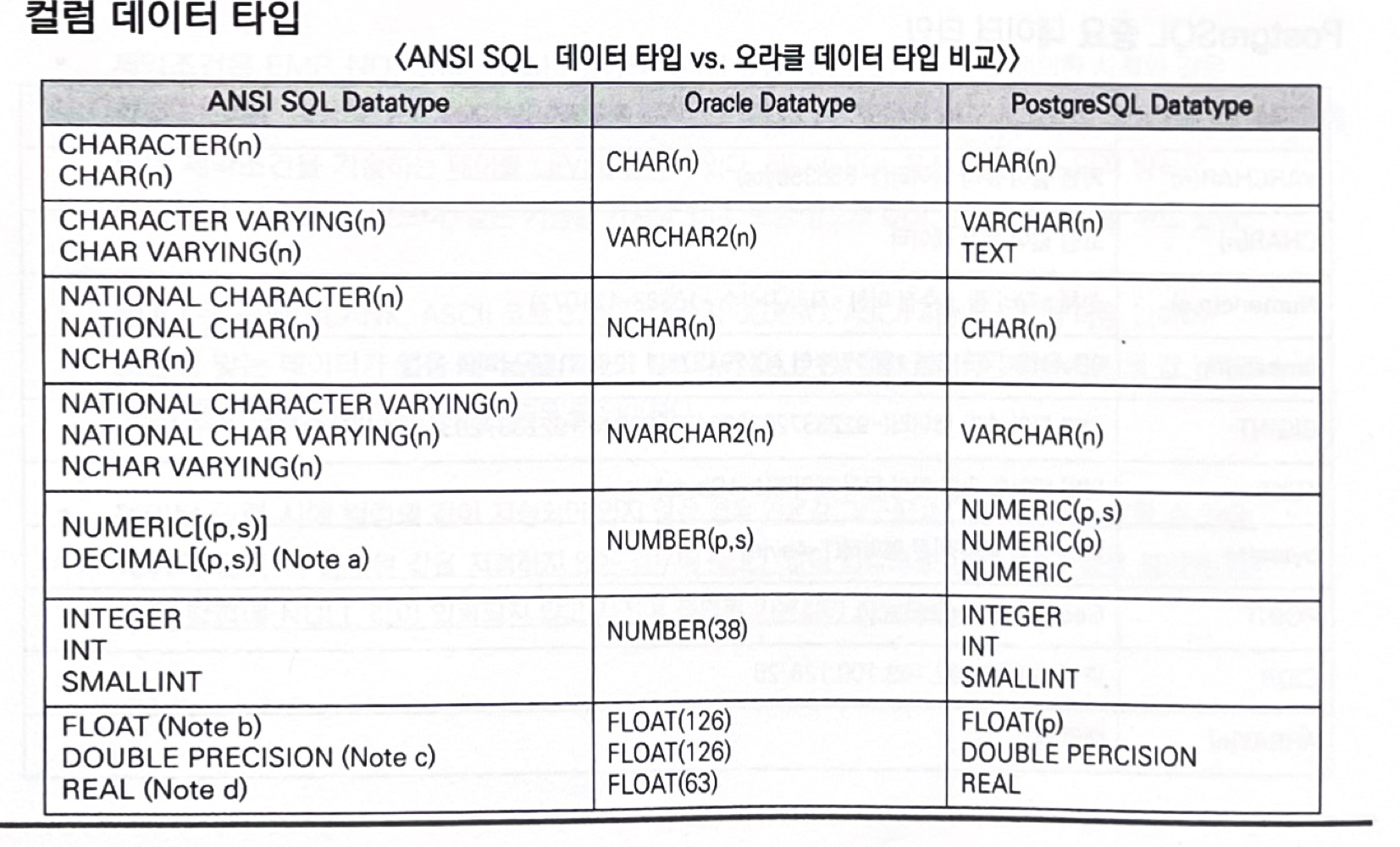
■ 테이블 제약 조건
- 데이터의 무결성 유지를 위해 사용자가 지정할 수 잇는 성질이다.
- PRIMARY KEY, FOREIGN KEY, UNIQUE KEY, NOT NULL, CHECK 가 있다.
- NULL 은 공백이나 숫자0과는 전혀 다른 값이다. '아직 정의되지 않은 값' 이거나 '데이터를 입력하지 못하는 경우' 이다.
- NULL 을 입력하고 싶지 않다면, 기본값 (DEFAULT) 를 사전에 설정할 수있다.
- NULL 은 초기값이 아니고, 다른 NULL이나 다른 값과 비교를 할 수 없다.
- DEFAULT 데이터 타입 값은 반드시 COLUMN 데이터 타입과 일치해야 한다.
CREATE TABLE 명령어를 사용해서 테이블을 복사할 수 있다. (보통 백업할 때 많이 사용함)
제약 조건이나 트리거, 테이블 권한은 복사되지 않으며, 제약조건은 NOT NULL 제약조건만 복사된다.
CREATE TABLE [schema.]table_name
[LOGGING | NOLOGGING]
[...]
AS
subquery
# 예제
CREATE TABLE TB_TEST1
AS
SELECT * FROM TB_EMP; (TB_EMP 전체를 불러오는 예제)사실 이렇게 보면 나도 음 ?싶다 ... 실습할 땐 괜찮았는데 ..?
테이블 관리는 ADD, RENAME, ALTER COLUMN, DROP 연산자를 통해 관리한다.
위에서 설명했으니 생략. (귀찮은 거 절대 아님)
ALTER TABLE
ALTER TABLE 테이블명
ADD COLUMN 컬럼명 데이터타입;
ALTER TABLE TB_TEST1
ADD COLUMN ADDRESS VARCHAR(80); #VARCHAR 타입은 가변길이 문자 데이터이다. 80가변길이인것임그럼 TB_TEST1 의 타입이 ADDRESS Type 이 VARCHAR 타입으로 변경된다.
DROP
ALTER TABLE 테이블명
DROP COLUMN 삭제할 컬럼명;
ALTER TABLE TB_TEST1
DROP COLUMN ADDRESS;사실 DROP 은 모르는 게 나을 것 같기도 하다. 데이터를 함부로 지우면 복구할 수 없기 때문에 ..ㅠ
MODIFY (컬럼 변경)
ALTER TABLE table)name
ALTER COLUMN column_name TYPE datatype
ALTER COLUMN column_name SET constraint
ALTER COLUNN column_name DROP constraint
ALTER TALBE TB_TEST1 ALTER COLUMN EMP_NAME TYPE VARCHAR(50);
ALTER TALBE TB_TEST1 ALTER COLUMN EMP_NAME SET NOT NULL;
ALTER TABLE TB_TEST1 ALTER COLUMN EMP_NAME DROP NOT NULL;테이블에 존재하는 컬럼에 대해 MODIFY 명령어를 사용해 컬럼의 데이터 유형, 기본값 (DEFAULT VALUE), NOT NULL 제약조건에 대한 변경이 가능하다.
RENAME(이름 변경)
ALTER TABLE 테이블명
RENAME COLUMN '변경해야 할 컬럼명' TO '새로운 컬럼명';
ALTER TALBE TB_TEST1
RENAME COLUMN LAST_NAME TO AERIM_NAME;기본키, 외래키, 고유키 같은 컬럼은 제약조근을 제거한 후에 이름 변경이 가능하다.
TRUNCATE TABLE
테이블의 모든 Row 를 삭제한다.
테이블이 사용한 저장공간도 해제한다. Truncate 로 삭제한 Raw 는 Rollback 이 불가능하다.
그래서 하기 전에 한 번 더 꼭 꼭 생각하기.
Delete 구문으로도 Row 를 삭제할 수 있지만 저장공간을 해제하진 않아서 Rollback 이 가능하다.
그래서 할거면 가능한 Delete 를 쓰기. (근데 실행 시간이 오래 걸릴 것이다.)
나도 TRUNCATE 구문을 괜히 알고 싶지 않으므로 실습 안 할 것이다. (절대 귀찮은 것이 아니다.)
DROP TABLE
테이블 안의 모든 데이터 & 구조를 삭제한다.
자동 COMMIT (와 진짜 무섭다)
모든 인덱스가 삭제된다. ROLLBACK 도 불가능하다.
테이블 생성자, 또는 DROP ANY TABLE 권한이 있는 사람만 삭제가 가능하다.
이건 잘못 드롭하면 진짜 답이 없을 것 같다. 그러므로 실습 안 하겠다.
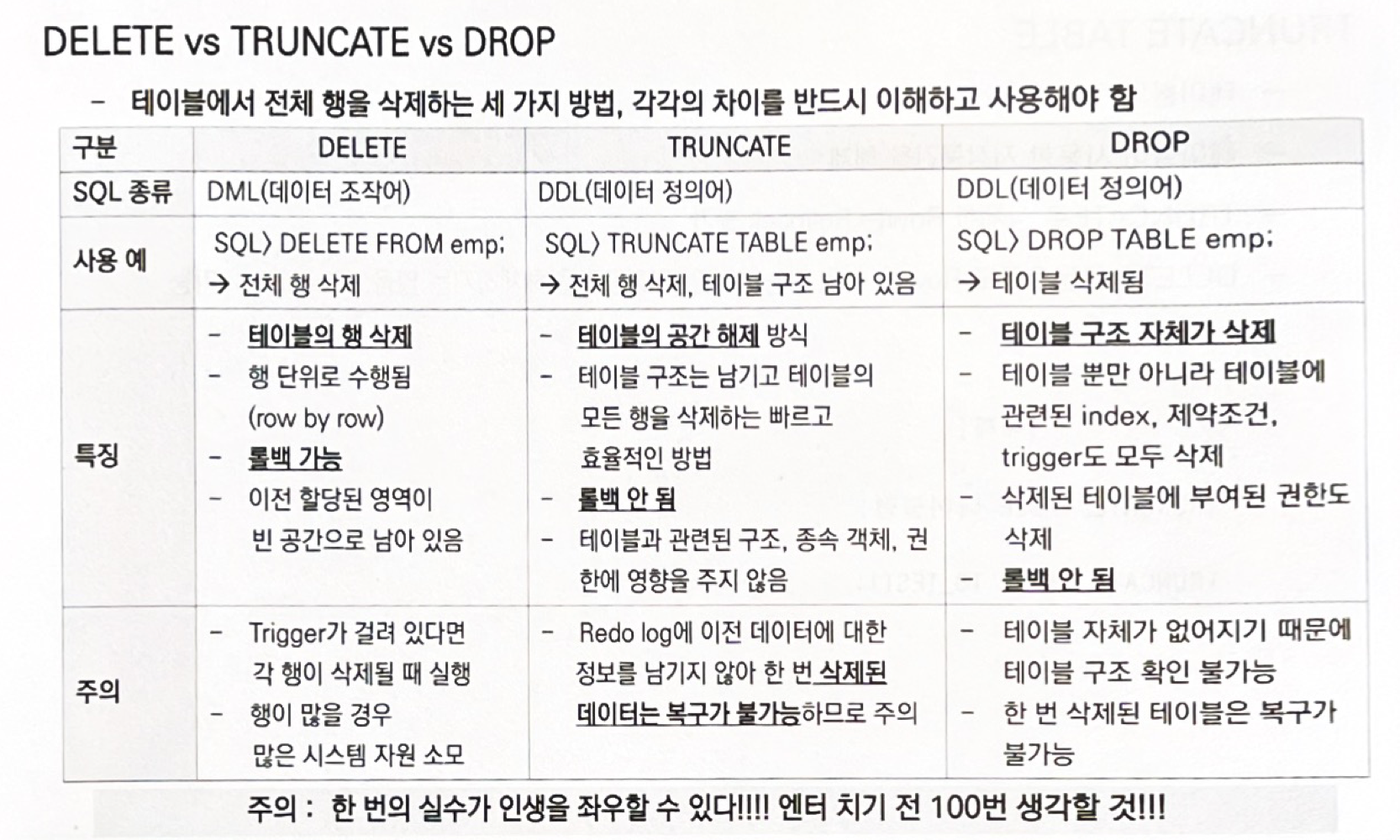
우리 모두 괜히 데이터를 삭제했다가 인생을 좌우할 실수를 하지 말도록 하자.
DELETE 가 가장 라이트하긴 하나.. 데이터가 많은 경우 엄청난 시간이 소요되므로...
괜히 데이터를 건드리지 말도록 하자.
요약
CREATE TABLE = 테이블 생성
ALTER TABLE = 테이블 구조 변경
DROP TABLE = 알지 마세요
RENAME = 이름 변경
TRUNCATE = 알지 마세요
아직 DDL까지밖에 하지 않았다는 사실이 너무 무서워 ...
아직도 적을 것이 산더미이다 ...

※ 저의 모든 데이터 분석 자료는 모두 공공 빅데이터 청년 인턴 교재들을 참고합니다.
'Data Science > SQL' 카테고리의 다른 글
| [Data/SQL] SQlite3 DBeaver 에 DB파일 넣기 (3) | 2022.09.13 |
|---|---|
| SQL을 이용한 정형 데이터 다루기(SQL응용) - 조인(JOIN) (2) | 2022.07.14 |
| SQL을 이용한 정형 데이터 다루기(SQL응용) - 집계 쿼리(집계 함수, GROUP BY, HAVING 절) (2) | 2022.07.13 |
| SQL을 이용한 정형 데이터 다루기(SQL응용) - SQL 함수 (문자형, 숫자형, 날짜, 변환함수, CASE, NULL 관련 함수(COALESCE) ) (2) | 2022.07.10 |
| SQL을 이용한 정형 데이터 다루기 - DML, WHERE절, ORDER BY절 (2) | 2022.07.05 |



