
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Keras
- data
- 공공빅데이터청년인턴
- k-means
- datascience
- ADSP
- SQL
- 머신러닝
- 2023공공빅데이터청년인재양성후기
- 2023공공빅데이터청년인재양성
- 데이터전처리
- 2023공빅데
- ADsP3과목
- DL
- 빅데이터
- 텍스트마이닝
- decisiontree
- 분석변수처리
- ML
- 오버샘플링
- 데이터분석
- textmining
- NLP
- 공빅데
- DeepLearning
- Kaggle
- 공빅
- 공공빅데이터청년인재양성
- machinelearning
- 클러스터링
- Today
- Total
愛林
Python으로 배우는 데이터 전처리 이해(II) - 분석변수 처리 - 파생변수(Derived variance) 생성 본문
Python으로 배우는 데이터 전처리 이해(II) - 분석변수 처리 - 파생변수(Derived variance) 생성
愛林 2022. 7. 9. 02:33
Intro
앞서서 분석변수 처리에 대해서 알아보았다.
https://wndofla123.tistory.com/26
Python으로 배우는 데이터 전처리 이해(II) - 분석 변수 처리란? , 변수 선택 - 필터기법
분석 변수 처리란 ? 분석 변수 처리란 확보한 데이터를 사용하여 정보를 추가하는 일련의 과정이며, 새로운 데이터(관측치나 변수) 를 추가하지 않고도 기존의 데이터를 보다 유용하게 만드는
wndofla123.tistory.com
분석변수 처리는 기존의 데이터를 유용하게 만드는 방법이라고 했다.
필요한 것만 뽑아서, 분석할 만한 변수만 뽑아서 처리를 하면 간단하고 깔끔해진다.
분석변수 처리에는 데이터 축소, 파생변수 생성, 데이터 변환, 불균형 데이터 처리가 있다.
앞서서는 데이터 축소에 대해서 설명하고, 데이터 축소 기법의 하나인 필터기법을 실습했다.
필터 기법 중에서도 분산을 활용한 기법, 상관계수를 통한 기법을 실습해보았다.
오늘은 분석 변수 처리 기법 중 하나인 파생변수 생성법에 대해서 알아보자.
파생변수 생성 (Derived Variance)
파생변수 생성이란 기존 변수에 특정 조건 또는 함수 등을 활용해서 새로운 변수를 만들거나,
기존 변수들을 조합해서 새롭게 만들어진 변수를 생성하는 것 이다.
디테일함을 추가할 수 있는 변수이다.
비즈니스 도메인을 이해하고 있는 데이터 분석가들에 의해서 만들어지는 경우가 많기 때문에
주관적일 수 있으나 유의미한 특성들이 객관적으로 반영되어있다. 즉, 편향이 발생 가능하다.
그렇기 때문에 파생변수를 생성할 때는 그 변수를 생성한 명확한 논리성이 필요하다.
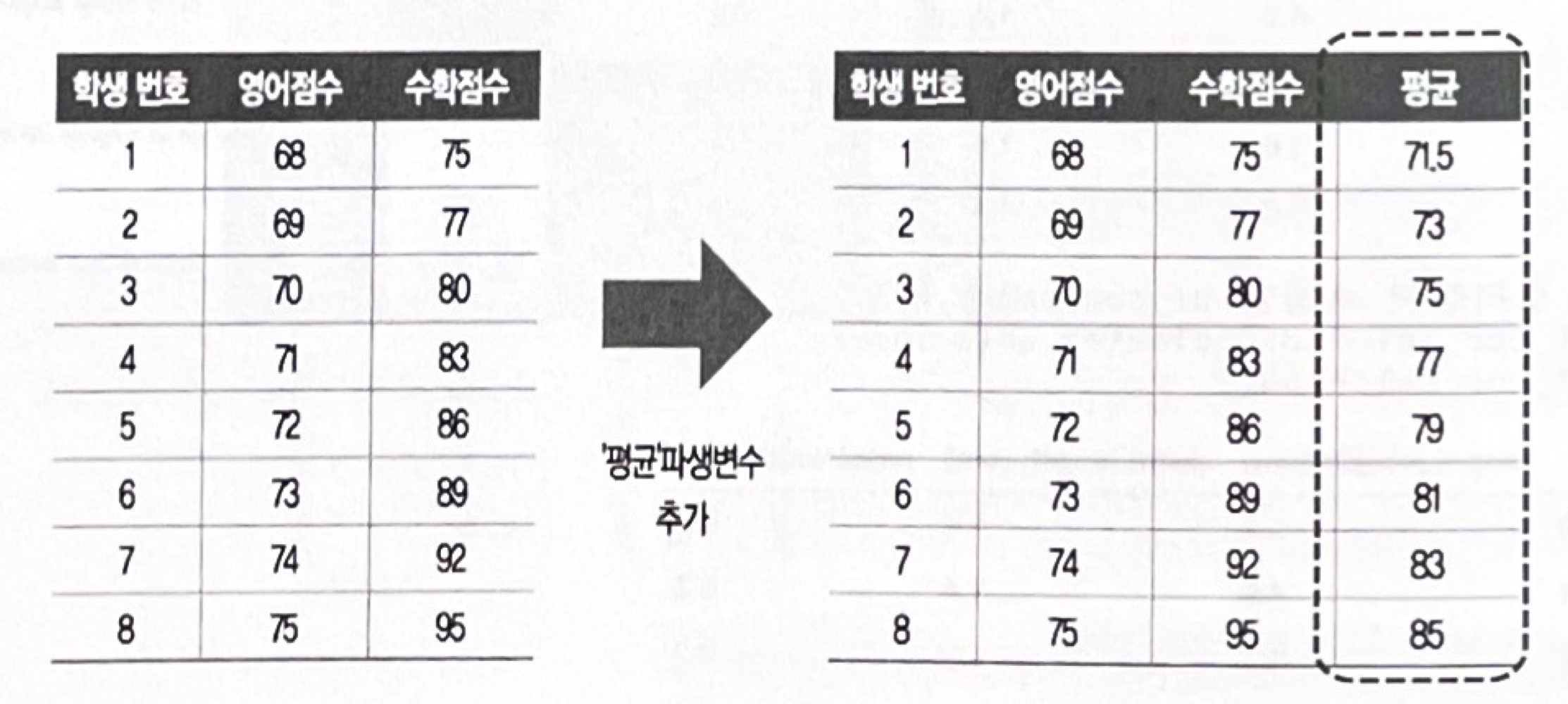
파생변수 중에서는 요약변수 (Summary Variable) 이라는 변수가 있는데,
데이터를 분석에 맞게 종합한 변수이다. 많은 모델을 공통으로 사용할 수 있어서 재활용성이 높은 것이 특징이다.
말 그대로 데이터를 요약해서 정리한 변수.

이해하기 어려운 개념은 아니니,
바로 실습에 들어가보자.
실습
역시나 실습 전,
필요한 라이브러리들을 불러오고 데이터셋을 준비해보자.

# 데이터셋 준비
# BMI, 체지방지수를 보기 위한 데이터
data = {'이름': ['홍길동','성춘향','이몽룡','김철수','김영희','김만수','오지랖',
'만순이','문정억','백만원','천만원','수십억','현재미' ],
'몸무게': [95,85,75,70,65,55,120,100,71,65,75,100,77],
'키': [170,170,170,170,170,175,171,165,164,177,163,192,182],
'거주지': ['서울','대구','대전','서울','경북','서울','경북','서울',
'서울','전남','전북','경북','서울'],
'주민번호': ['81XXXX-1XXXXXX','81XXXX-1XXXXXX','79XXXX-2XXXXXX','71XXXX-1XXXXXX',
'65XXXX-2XXXXXX','81XXXX-1XXXXXX','63XXXX-1XXXXXX','81XXXX-3XXXXXX',
'81XXXX-1234562','55XXXX-1234562','71XXXX-2234562','92XXXX-1234562',
'85XXXX-2234562'],
'흡연여부': ['흡연','미흡연','미흡연','흡연','흡연','미흡연','흡연','흡연','흡연',
'미흡연','미흡연','미흡연','미흡연']
}
df = pd.DataFrame(data)BMI, 체지방 지수를 보기 위한 데이터를 준비했다.
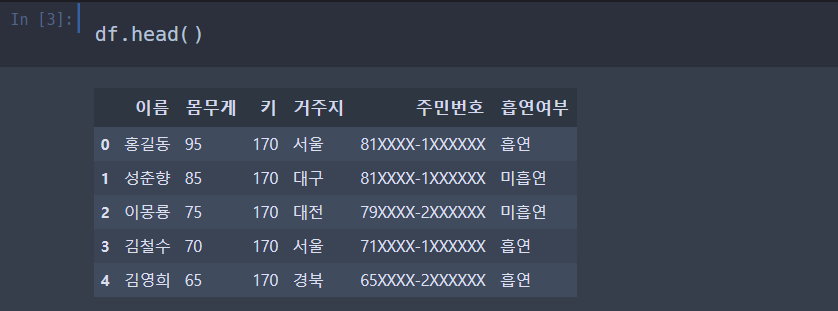
이번에도 이상없이 잘 만들어진 듯 하다.
이것저것 변수를 손봐주어야 하니, 방금 만든 데이터프레임을 copy() 해주자.
copy 한 데이터프레임의 이름은 df_mod 이다.
df_mod = df.copy()

파생변수를 생성해주었다.
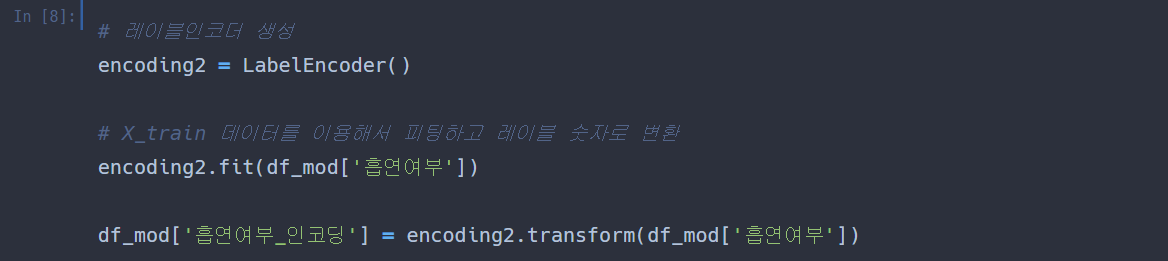
이름 변수는 '이름_인코딩' 이라는 변수로 바꾸어줄 것이다,
먼저 레이블인코더를 생성해주었다.
+
레이블인코더(LabelEncoder) 는 앞서 배웠던 건데, 문자형 값들을
코드형 숫자값으로 변경시켜주는 것이다. 머신러닝을 할 때, 알고리즘이 이해하기 편하게 바꾸어주는 과정이다.
이후, X변수에 이름이라는 데이터를 피팅해주고, 방금 전의 레이블인코더에 돌려서
이름 데이터를 레이블 숫자로 변환시켜주었다.
이후 df_mod 안의 이름_인코딩 이라는 변수 안에 저장해주었다.

encoding_classes_ 를 활용해서 문자열 값이 어떻게 인코딩 되었는 지 알 수 있다.
김민수, 김영희 ,김철수, 만순이...... 가
각각 0,1,2,3 으로 바꾸어져서 입력이 된 것을 확인했다.
inverse_transform 을 이용해서 1,0 값이 김영희, 김민수라고 나왔으니 위의 내용이 확인이 된 것이다.
이번에는 흡연여부를 사용해서 '흡연여부_인코딩' 이라는 파생변수를 생성했다.
encoding2 라는 레이블인코더를 사용해서 흡연여부를 독립변수로 피팅한 것을 확인해보자.
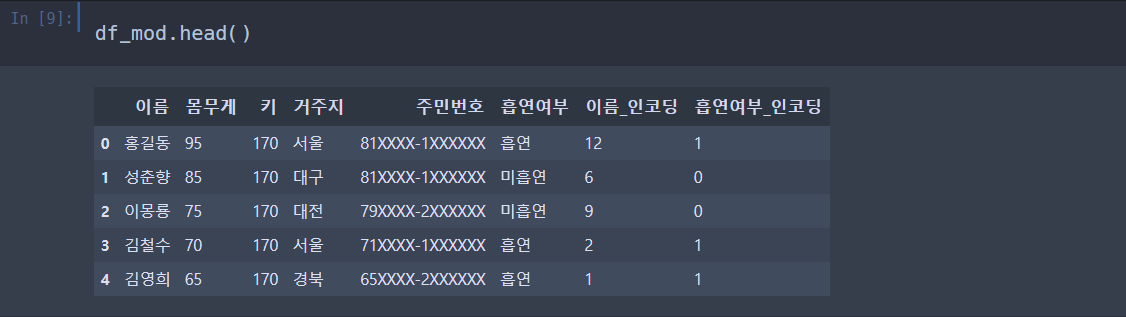
우옷ㅋ
우리가 만든 변수들이 잘 생성이 된 것 같다.
숫자로도 잘 바뀌었다.
이번엔 나이 변수를 생성해보겠다.
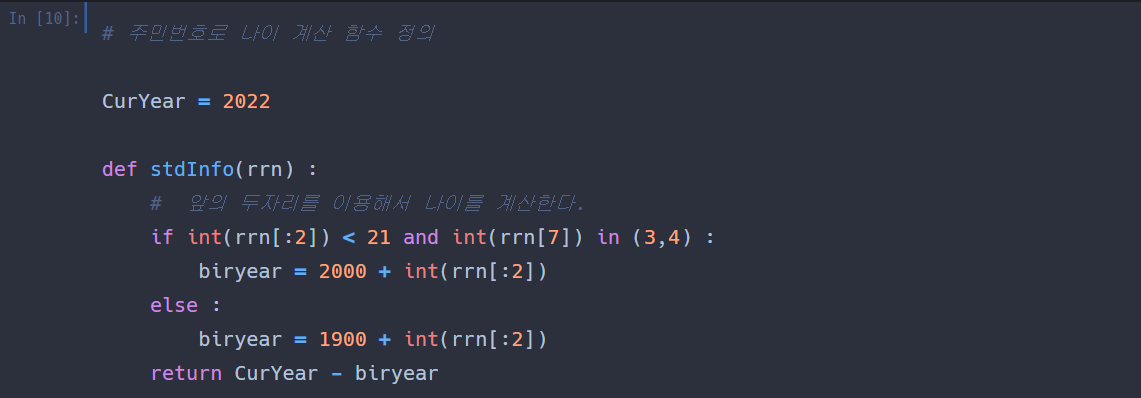
먼저 지금 년도 변수를 만들어주고,
stdInfo() 라는 나이를 계산하는 변수를 만들어주었다.
변수가 잘 작동되는지 나의 주민번호 .. 를 입력해서 확인해보겠다.

변수가 잘 작동되는 것 같다. 근데 나는 23살인데..
한국 나이로 할려면 +1 을 해주어야 할 것 같다.
나는 한 살이라도 적은 것이 좋으니 그냥 이 나이 변수를 사용하겠다.

나이 컬럼을 생성해주고, 주민번호에 stdInfo() 함수를 apply 시켜서 넣어주었다.
데이터 프레임을 확인해보니 잘 생성된 것 같다. (물론 한 살 어린 채로 ^^)
이번에는 성별 변수를 생성해보자.
이번에도 성별을 계산하는 sex() 함수를 먼저 생성하고 가겠다.
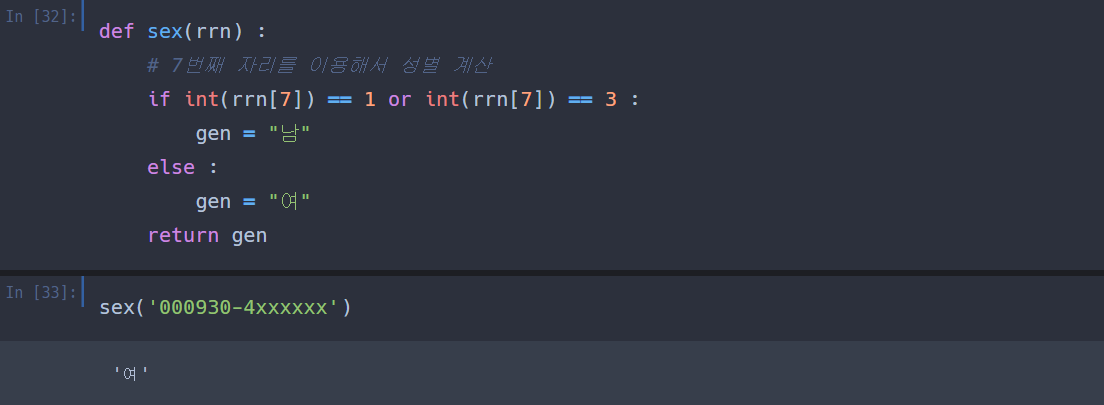
역시나 잘 생성되었다.
내 주민번호 7번째 자리는 4니까 여 가 출력되는 것이 맞다.
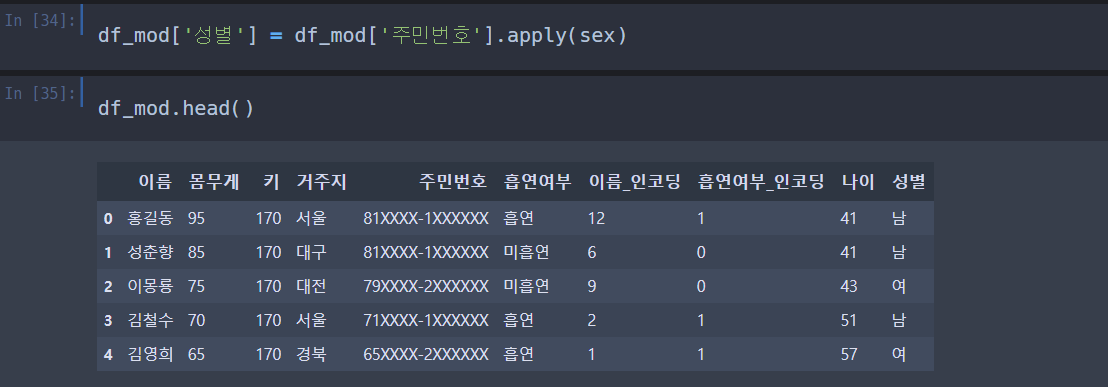
성별 변수가 잘 생겼다 !
이번에는 One-Hot encoding 을 사용해서 성별을 레이블 숫자 형태로 바꾸어 보자.
+
One-Hot Encoding
글도 못 읽는 바보같은 인공지능에게 0,1 형태로 데이터를 알려주는 인코딩 기법이다.
수많은 0들 사이에 우리가 보고 싶은 데이터만 1 로 표시한다.
보통 True, False 에 많이 쓰이는 것 같다.
OneHotEncoder 를 통해 쓴다.
sparse = True 인 경우 (행, 열) 1 의 좌표리스트 형식,
False 의 경우 넘파이 배열로 반환한다.

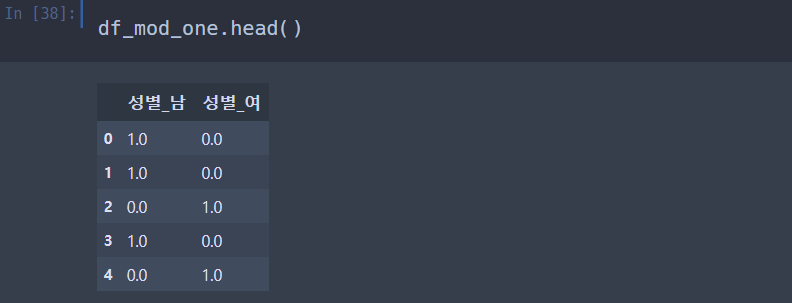
잘 나왔군.
df_mod 에 concat 을 이용해서 합쳐주도록 하자.
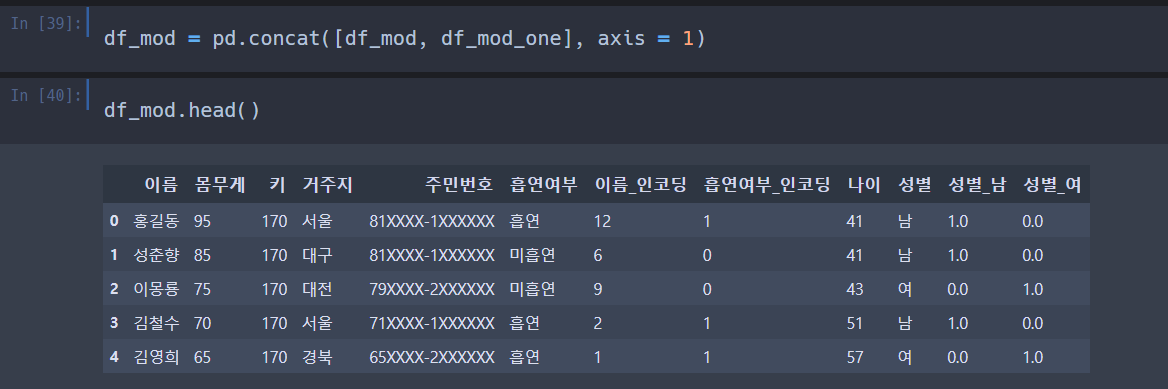
옆 성별 칼럼도 확인해보니 잘 나온 것 같다.
이번엔 나이 변수의 범주화 변수를 생성해주겠다.
pd.cut() 함수를 사용하겠다.
pd.cut () : 연속된 수치를 구간으로 나누어 카테고리화 할 때 사용
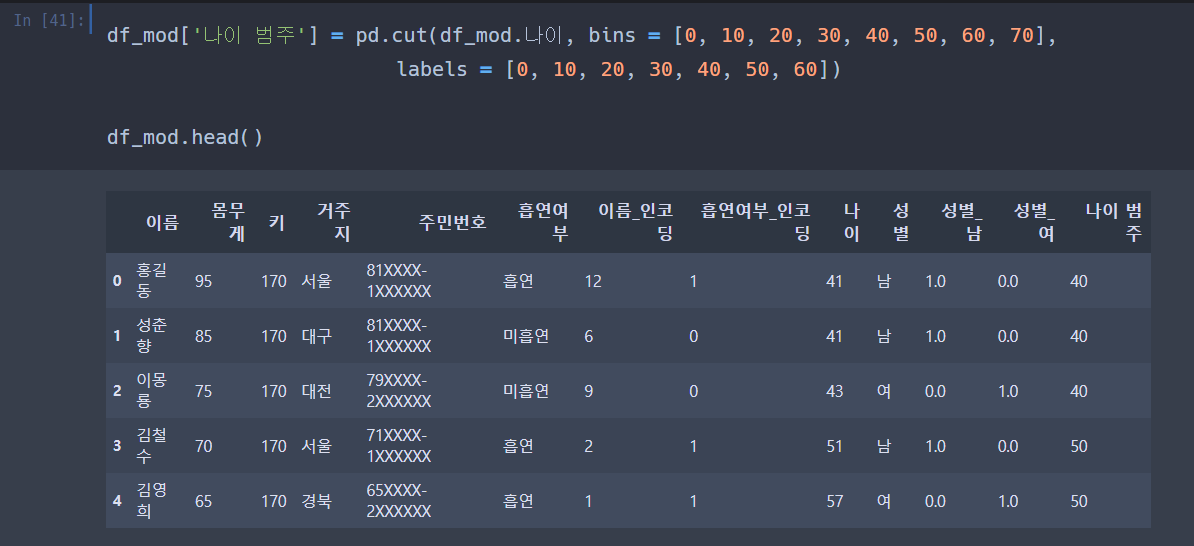
열이 좀 밀리긴 했는데
아무튼 간에 잘 나왔다.
41세 홍길동씨의 나이 범주는 40, 51세 김철수씨의 나이 범주는 50이니 잘 나온 것이다.
BMI 변수를 생성해주자.
BMI 는 체질량 지수도, 인간의 비만도를 나타내는 지수이다.
몸무게 / (((키/100) * (키/100)) 으로 계산한다.
eval() 함수를 사용해서 만들것이다.
eval() : 문자열로 된 수식을 input 으로 받아서 그 결과를 return 하는 함수
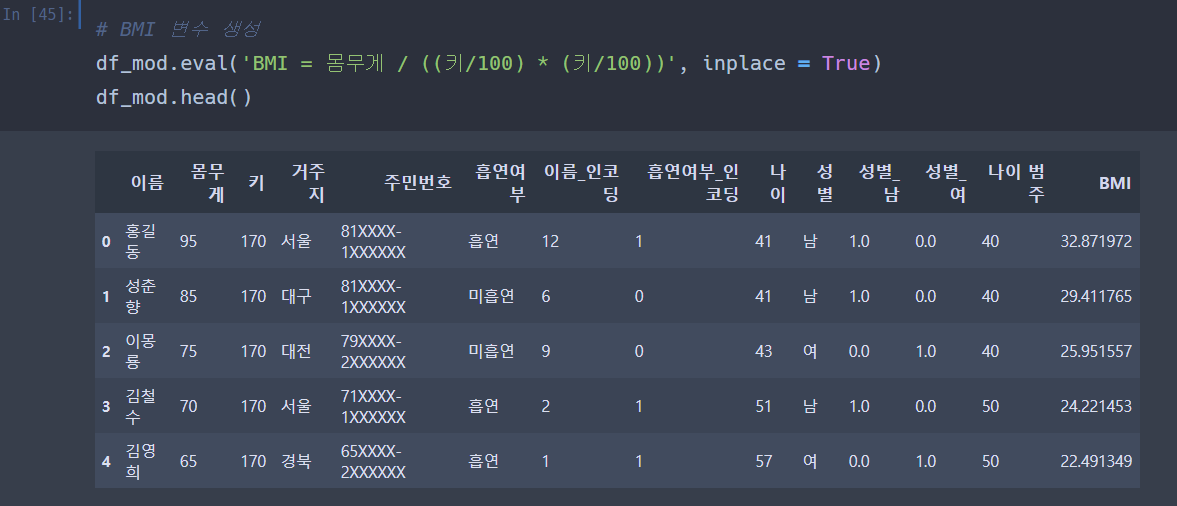
오..eval() 을 쓰면 바로 데이터프레임에 저렇게 들어가는구나 ..
아무튼 BMI지수만 확인했다.
이제 BMI 를 분류해서 누가 비만인지 가려보자.

pd.cut() 을 이용해서 0, 18, 23, 25, 30, 90 을 저체중, 정상 등으로 끊어서 BMI 분류 컬럼에 넣었고,
map() 을 통해서 분류코드를 0,1,2 .. 로 주어서 레이블을 숫자형으로 바꾸어주었다.
이제 우리가 만든 변수들만 꺼내서 데이터프레임을 만들어보자.
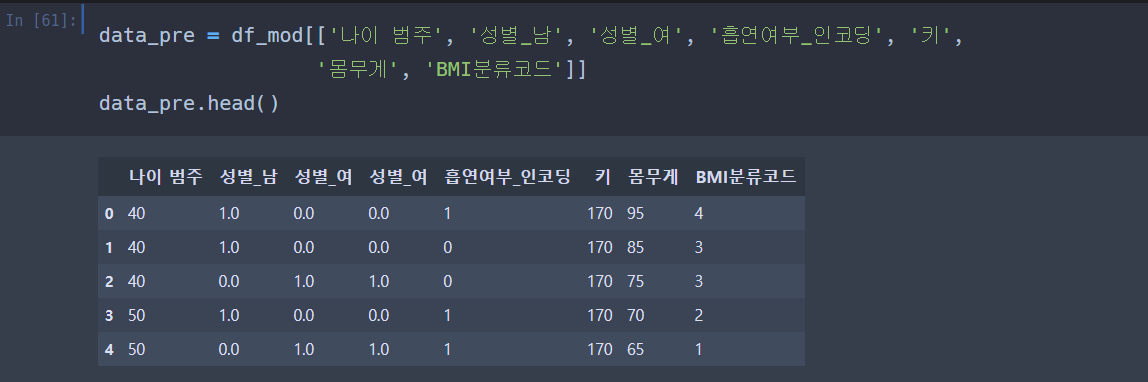
내가 만든 파생변수들로 데이터 프레임 완 - 성

Review
데이터 전처리 과정에는 데이터 정제와 분석 변수 처리가 있다.
분석 변수 처리에는 또 데이터 축소, 파생변수 생성, 데이터 변환, 불균형 데이터 처리가 있다.
이번에는 데이터 전처리의 분석 변수 처리 중 파생변수 생성을 실습해보았다.
사실 지금까지 실습을 해오면서 우리는 그냥 인지도 하지 못 한 채 파생변수를 생성해온 것이나
마찬가지이다 .
파생변수 생성은 기존 변수에 특정 조건이나 함수를 이용해 새로운 변수를 만들거나,
기존 변수를 조합하거나 바꾸어서 새롭게 변수를 만드는 것이다.
변수 생성에 따라서 주관적 의사가 반영이 될 수 있기 때문에 데이터의 편향 문제 발생 가능성이 높다.
그러므로 우리는 파생변수를 생성할 때 논리적 타당성을 명확하게 하고 생성해야 한다.
우리가 왜 이 파생변수를 만드는 지 가 명확해야 한다고 보면 된다.
잘만 활용하면 데이터 분석 모델에서 아주아주 유의미하게, 요긴하게 쓰이므로 잘 알아두자.
'Data Science > DATA' 카테고리의 다른 글
| Python으로 배우는 데이터 전처리 이해(II) - 분석변수 처리 - 변수 변환(Variable Transformation) (2) - Min-Max 정규화 (2) | 2022.07.10 |
|---|---|
| Python으로 배우는 데이터 전처리 이해(II) - 분석변수 처리 - 변수 변환(Variable Transformation) (1) - 로그(Log)변환 (2) | 2022.07.10 |
| Python으로 배우는 데이터 전처리 이해(II) - 분석 변수 처리란? , 변수 선택 - 필터(Filter)기법 (3) | 2022.07.09 |
| Python으로 배우는 데이터 전처리 이해(I) - 이상값(Outlier)처리 (2) | 2022.07.06 |
| Python으로 배우는 데이터 전처리 이해(I) - 결측값 처리 (4) | 2022.07.06 |



