
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Keras
- 공빅데
- 공빅
- textmining
- SQL
- 공공빅데이터청년인재양성
- ML
- datascience
- NLP
- DeepLearning
- 텍스트마이닝
- 빅데이터
- 머신러닝
- 2023공공빅데이터청년인재양성후기
- 2023공빅데
- data
- ADSP
- 데이터분석
- k-means
- machinelearning
- 분석변수처리
- 오버샘플링
- 공공빅데이터청년인턴
- Kaggle
- DL
- ADsP3과목
- 데이터전처리
- 2023공공빅데이터청년인재양성
- decisiontree
- 클러스터링
- Today
- Total
愛林
[Python/Data] 시각화 실습 / Seaborn 패키지 / matplotlib 본문
시각화
데이터 시각화를 통해 데이터를 그래프나 차트로 시각화함으로써 데이터 안에 숨겨진 정보를
효율적으로 파악하며, 데이터에 내재된 트랜드 이상치, 패턴 등을 파악할 수 있다.

긴 말 필요없이, 바로 실습을 진행하면서
시각화 데이터를 알아보도록 하자.
데이터 시각화 실습
import pandas as pd
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
# 깨짐 방지를 위한 Font 지정
import os
if os.name =='nt' :
font_family = "Malgun Gothic"
else :
font_family = "AppleGothic"
# 값이 깨지는 문제 해결을 위해 파라미터값 설정
sns.set(font=font_family, rc = {"axes.unicode_minus" : False})
우리가 사용할 주 시각화 패키지는 seaborn, matplotlib 이다.
seaborn 은 matplotlib를 바탕으로 하고 있는 시각화 패키지이다.
# tip data load
data = sns.load_dataset('tips')
tips 데이터를 이용해서 시각화를 알아보자.
tips 데이터는 seaborn 라이브러리에서 기본적으로 제공하는 데이터셋이다.
레스토랑에 방문한 손님이 팁을 얼마나 주는 지, 성별, 흡연여부 ,요일, 식사시간, 식사인원 등에 대한
정보를 가지고 있는 데이터셋이다.

막대 그래프 (Bar Chart)
보통 사물의 양을 막대 모양의 길이로 나타낸 그래프이다.
비교 시각화가 가능하며, 크고 작은 데이터의 크기를 한 눈에 이해할 수 있다.
matplotlib 로 막대그래프 시각화하기.
label = ['Thur', 'Fri', 'Sat', 'Sun']
plt.bar(label, tips_sum_day, width = 0.5, align = 'edge')<BarContainer object of 4 artists>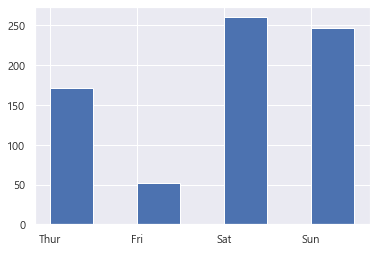
plt.bar(x축, y축, width = 폭, align = 눈금과 막대위치 'egde' )
label 은 x축 데이터, tips_sum_day 는 values, y축 데이터, width 는 막대의 축, align 은 눈금과 막대 위치를
조절하는 것이다. 우리는 'edge' 를 사용했으므로 왼쪽 끝에 눈금을 표시한다. (Thur, Fri, Sat, Sun..)
성별(Sex) 와 평균 팁(tip) 을 비교해보자.
이번에는 matplotlib 가 아닌, seaborn 을 사용해볼 것이다, sns 로 사용한다.
sns.barplot(data = data, x = 'sex', y = 'tip')
sns.bawrplot(data = data, x = , y = ) 를 사용한다.
<AxesSubplot:xlabel='sex', ylabel='tip'>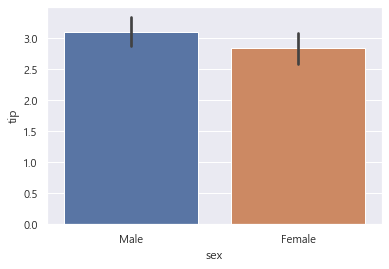
이번에는 식사인원별 (size)
남성과 여성의 팁을 비교해보자.
plt.figure(figsize = (10,5))
sns.barplot(data=data, x = 'sex', y='tip', hue='size')<AxesSubplot:xlabel='sex', ylabel='tip'>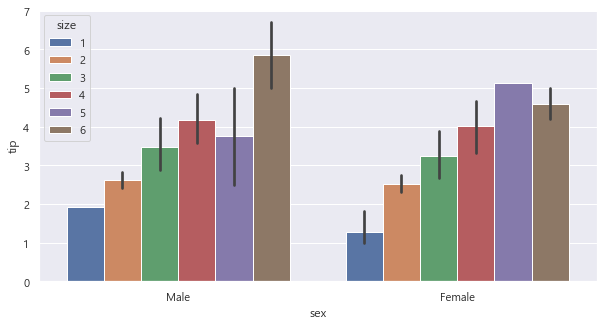
hue = "size" 는 범례를 표시해주고,
size 별로 나누어준다는 뜻이다. 색색별로 나누어진 것을 보면 size 별로 잘 나누어진 것을 볼 수 있다.
상자 그림 (Box - Plot)
박스 그림은 데이터의 분포를 보여주며 사분위수와 사분위수 범위, 그리고 이상치를
시각화해서 보여주는 데에 용이하다.
특히 이상치를 보여주는 데에 많이 사용된다.
# 백분위수 계산(percentile)
print(data['tip'].quantile([0.05, 0.25, 0.5, 0.75, 0.95]))
print('\n')
percentages = [0.05, 0.25, 0.5, 0.75, 0.95]
df = pd.DataFrame(data['tip'].quantile(percentages))
df.index = [f'{p * 100}%' for p in percentages]
print(df.transpose())0.05 1.4400
0.25 2.0000
0.50 2.9000
0.75 3.5625
0.95 5.1955
Name: tip, dtype: float64
5.0% 25.0% 50.0% 75.0% 95.0%
tip 1.44 2.0 2.9 3.5625 5.1955
tips 의 tip 데이터에 대한 시각화.
# 한 변수에 대한 이상값 시각화
ax = (data['tip']).plot.box()
ax.set_ylabel('달러($)')ax 에 tip 데이터를 시각화하는 것을 저장한다.
시각화하면서, y축은 '달러($)' 로 label 를 달아준다.

이제 전체 변수를 상자 그림으로 그려보자.
우리는 seaborn 패키지. sns 를 사용한다.
plt.figure(figsize = (10,5))
sns.boxplot(data = data, orient = 'h')
plt.show()가로 10, 세로 5
sns.boxplot(data = data , orient = 'h' or 'v' ) 를 사용한다.
orient 값이 'h' 이면 horizon. 가로형
orient 값이 'v' 이면 vertical , 세로형이다.

도수분포표 & 히스토그램 시각화
도수분포표 (Frequency table)
는 데이터 각 값의 출현 도수를 세거나 몇 개의 구간으로 나누어서
각 구간에 속하는 데이터의 개수를 세어서 정리한 표이다.
하나의 (일변량) 범주형 변수에 빈도수를 파악하거나, 연속형 변수를 구간화해서 도수분포표로 분석한다.

이렇게 만든 도수분포표는 히스토그램으로 바꾸어서 시각화한다.
히스토그램(Histogram)
은 도수분포표의 각 계급의 양 끝을 가로축에 표시하고, 그 계급의 도수를
세로축에 표시해서 직사각형 모양으로 만들어내는 그래프이다.
가로축이 계급이고, 세로축이 도수이다. (반대로도 표현이 가능하다.)
상대도수, 상대 누적 도수 등을 확인할 수 있다.
pd.cut() 을 이용해서 연속된 수치를 구간으로 나누어 카테고리화 해보자.
bin_total = pd.cut(data['total_bill'], 8) # data를 8개 구간별로 잘라서 구간을 세어준다.
bin_total.value_counts()
total_bill 데이터를 8개 구간별로 잘라서 나누어주고, 이를 bin_total 변수 안에 저장했다.
(15.005, 20.972] 81
(9.038, 15.005] 68
(20.972, 26.94] 38
(26.94, 32.908] 24
(3.022, 9.038] 12
(32.908, 38.875] 10
(38.875, 44.842] 6
(44.842, 50.81] 5
Name: total_bill, dtype: int64
value_counts() 함수는
column 의 unique 한 변수들을 count 해주는 변수이다.
그러니까, 첫번째 구간 안에 있는 데이터 개수는 81개,
두 번째 구간 안에 있는 데이터 개수는 68개 ,
세 번째 구간은 38개가 들어있는 것이다.
이제 plt (matplotlib) 를 사용해서 히스토그램을 시각화해보자.
fig, axs = plt.subplots(1, 2, figsize=(10,5))
# 히스토그램
# plt.style.use('ggplot')
ax1 = plt.subplot(1,2,1)
ax1 = (data['total_bill']) . plot.hist(bins = 8) #bins 구간 수
ax1.set_xlabel('total_bill($)')plt. subplots() 를 사용한다.
plt.subplot 도 사용가능하다. 근데 s 를 붙여주지 않으면 하나하나 다 설정해야 한다.
우리는 subplots () 를 이용해서 한 번에 설정해주도록 하자.
Text(0.5, 0, 'total_bill($)')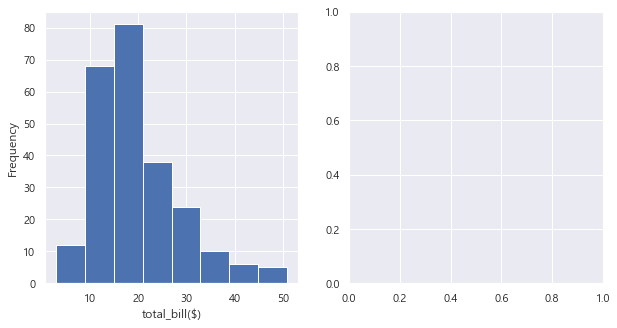
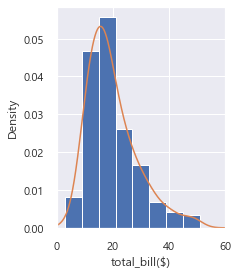
이젠 밀도그림을 이용해보자.
plt.subplot(1,2,2)
ax2 = data['total_bill'].plot.hist(density = True, xlim = [0,60], bins=8)
data['total_bill'].plot.density(ax=ax2);
ax2.set_xlabel('total_bill($)')
plt.tight_layout()
plt.show()plot.hist() 를 사용한다.
hist () 안의 bins 는 구간의 개수를 뜻한다.
여기서는 bins = 8 이니 구간이 8개임을 보여준다.
plot.density() 는 밀도를 보여주는 것이다.
그러니까, 선을 그려주었다.
위로 올려서 붙이면

'Data Science > Python' 카테고리의 다른 글
| [Python] 파이썬 다운그레이드 (Python downgrade), 버전 변경(Python change version), Error. Solving environment: failed with initial frozen solve. Retrying with flexible solve (2) | 2023.01.06 |
|---|---|
| [Python] Python에서 Open API 불러오는 법 (2) | 2022.09.13 |
| Python Pandas (0) | 2022.06.26 |
| Python Numpy (3) | 2022.06.26 |
| Python Basic (2) | 2022.06.26 |


