
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ML
- machinelearning
- 오버샘플링
- 데이터전처리
- ADSP
- 빅데이터
- 머신러닝
- ADsP3과목
- NLP
- 텍스트마이닝
- SQL
- DeepLearning
- datascience
- data
- 클러스터링
- 분석변수처리
- 2023공공빅데이터청년인재양성후기
- k-means
- Kaggle
- 데이터분석
- 공공빅데이터청년인턴
- textmining
- 2023공빅데
- Keras
- decisiontree
- 2023공공빅데이터청년인재양성
- 공빅
- 공빅데
- 공공빅데이터청년인재양성
- DL
- Today
- Total
愛林
[Text Mining] 텍스트 마이닝 - KoNLPy 를 이용한 한글 워드클라우드(Wordcloud) 만들기 본문
[Text Mining] 텍스트 마이닝 - KoNLPy 를 이용한 한글 워드클라우드(Wordcloud) 만들기
愛林 2022. 7. 30. 16:06
이전에는 nltk 를 사용하여 이상한 나라의 앨리스 소설의
단어 빈도를 알아보고, 단어 빈도 그래프와 워드 클라우드를 만들어보았었다.
https://wndofla123.tistory.com/54
텍스트 마이닝(Text Mining) - 단어 빈도 분석, 그래프와 워드 클라우드 만들기
재밌는 워드 클라우드 만들기 ! 단어 빈도 분석 진행 후 그래프랑 워드 클라우드 만들기를 해보자. Intro 문서는 사용된 단어들의 빈도들만 파악해도 많은 정보를 얻을 수 있다. 이를 통해서 이 글
wndofla123.tistory.com
이번에는 한글 단어 빈도 그래프와 워드 클라우드를 만들어보자.
한글 문서의 단어 빈도 그래프
대한민국 헌법의 단어 빈도를 세어보고, 워드 클라우드를 만드는 실습을 진행해보자.
from konlpy.corpus import kolaw
konlpy 에는 kolaw(대한민국 법) 말뭉치(corpus) 가 제공된다.
이전에 nltk 에서 가져왔던 방법과 유사한 것으로 헌법 텍스트를 가져온다.
const_doc = kolaw.open('constitution.txt').read()
print(type(const_doc))
print(len(const_doc))
kolaw 에서 constitution(헌법) 파일을 읽어와 const_doc 에 저장해주었다.
const_doc 의 type 은 str . 텍스트 파일, len(텍스트 길이) 는 18884 이다.
이제 konlpy 를 사용해서 전처리를 해주자.
from konlpy.tag import Okt
t = Okt()
tokens_const = t.nouns(const_doc) #형태소 단위로 토큰화 후, 명사만 추출.
tokens_const = [token for token in tokens_const if len(token) > 1]
print('토큰의 수 :', len(tokens_const))
print('앞 10개의 토큰 :')
print(tokens_const[:10])
nouns(phrase) 는 주어진 텍스트를 형태소 단위로 분리한 후 토큰 중 명사만 변환
해주는 함수였다.
token 중 한 글자로 된 토큰은 제외시켰다.

토큰의 수는 3013 개,빈도가 가장 높은 10개의 토큰을 추출시켰다.
이제 이 토큰들로 한글 단어 빈도 그래프를 생성해보자.
import matplotlib.pyplot as plt
from matplotlib import font_manager , rc
%matplotlib inline
font_name = font_manager.FontProperties(fname = "c:/windows/Fonts/malgun.ttf").get_name()
rc('font', family = font_name)
const_word_count = dict()
for word in tokens_const :
const_word_count[word] = const_word_count.get(word, 0) + 1
sorted_word_count = sorted(const_word_count, key=const_word_count.get, reverse = True)
n=sorted_word_count[:20][::-1]
w = [const_word_count[key] for key in n]
plt.barh(range(len(n)), w, tick_label=n)
plt.show()
matplotlib 를 이용해서 plt.barh 로 단어 빈도 그래프를 생성했다.
폰트는 malgun.ttf 를 사용했다. 다른 폰트를 사용해도 된다.
이전에 했던 것처럼 단어별 빈도를 담을 딕셔너리를 생성하고, 빈도를 계산해주었다.
tokens_const 에서 단어가 있다면 숫자가 1씩 증가하도록 반복문을 사용하여 빈도를 세었다.
이후 빈도를 key 로 해서 단어를 빈도 역순으로 정렬하고
(역순으로 정렬하는 것은 빈도가 많은 순으로 출력하려고. 우린 오름차순이 아니라 내림차순으로 봐야하기 때문)
plt.barh 로 그래프를 출력했다.
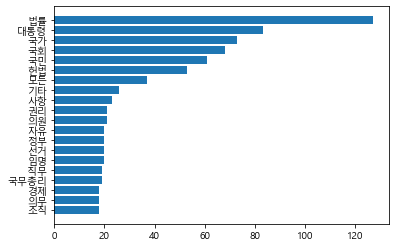
짜쟌 그래프 완성
이제 대한민국 헌법의 워드 클라우드를 생성해보자.
# WordCloud 객체에 전달할 폰트 주소 생성
font_path = "c:/Windows/Fonts/malgun.ttf"
wordcloud = WordCloud(
font_path = font_path,
max_font_size = 100,
width = 800,
height = 400,
background_color = 'white',
max_words = 50)
# 원문이 아닌 형태소 분석 결과로부터 워드 클라우드를 생성한다.
wordcloud.generate_from_frequencies(const_word_count)
plt.axis("off")
plt.imshow(wordcloud)
plt.show()
생성한 파일을 이미지 파일로 저장하고 싶다면
wordcloud.to_file("저장하고싶은이름.png") 로 저장할 수 있다.


짜쟌.
멋진 헌법 워드 클라우드 완성
※ 해당 자료는 모두 공공 빅데이터 청년 인턴 교육자료들을 참고합니다.
'Data Science > Text Mining, 자연어처리' 카테고리의 다른 글
| [Text Mining] 텍스트 마이닝 - Scikit learn 을 이용한 토픽 모델링(Topic Modeling), LDA (3) | 2022.08.28 |
|---|---|
| [Text Mining] 텍스트 마이닝 - 카운트 기반 문서 표현 (2) | 2022.08.27 |
| [Text Mining] 텍스트 마이닝 - 단어 빈도 분석, 그래프와 워드 클라우드 만들기 (2) | 2022.07.30 |
| [Text Mining] 텍스트 마이닝 - KoNLPy 를 사용한 한글 텍스트 전처리 (2) | 2022.07.30 |
| [Text Mining] 텍스트 마이닝 - 텍스트 전처리(Text Preprocessing) - 품사 태깅(POS-TAGGING) (2) | 2022.07.30 |



