SQL을 이용한 정형 데이터 다루기(SQL응용) - SQL 함수 (문자형, 숫자형, 날짜, 변환함수, CASE, NULL 관련 함수(COALESCE) )
Intro
글을 시작하기 전,
우리는 postgreSQL 을 사용한다.
그리고 DBeaver DBMS 를 사용한다.
교육장에서 나누어준 cslee.sql 파일을 사용한다.
저번 SQL 시간에는 (까마득)
DML 과 WHERE, ORDER BY 절에 대해 공부해보았다.
오늘은 SQL 함수에 대해 알아보고,
CASE 를 알아보자.
SQL 함수 (Function)
SQL 함수도 다른 프로그래밍 언어와 마찬가지로 어떤 값을 입력 받아, 정해진 어떤 로직을 실행하고
결과값을 출력한다.
스칼라 함수(1개 인수) , 그룹함수(여러 개 인수), 사용자 정의 함수 등이 있다.
함수의 입력값은 인수(Argument) 라고 하며, 인수의 개수는 0개 이상이다.
인수를 안 넣어도 값이 나오는 함수가 있다.
함수의 출력값은 반환값 (Return Value) 라고 하며, 반환값은 1개이다.
함수를 지정할 때에는 함수 이름 뒤에 괄호를 이용한다. 인수가 2개 이상일 때는 콤마로 분리한다.
스칼라 함수
스칼라 함수는 데이터 값을 조작한다. 인수를 받아들여, 한 개의 값을 반환한다.
Datatype 을 바꾸어 주고, 중첩또한 가능하다. (함수 안에 함수 넣기 가능)
문자 함수, 숫자함수, 날짜함수, 변환함수, NULL 관련 함수들이 있다.
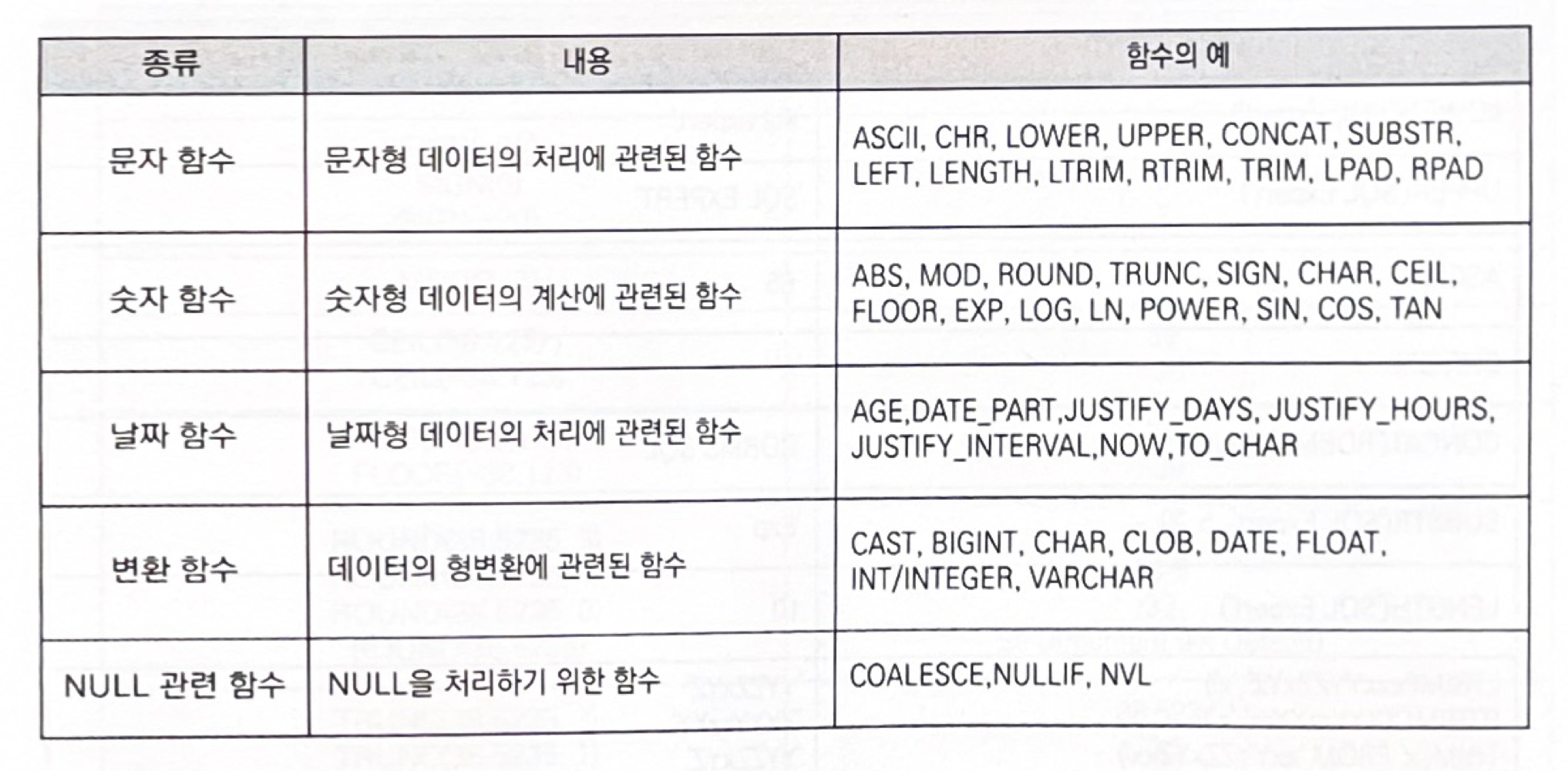
■ 문자형 함수
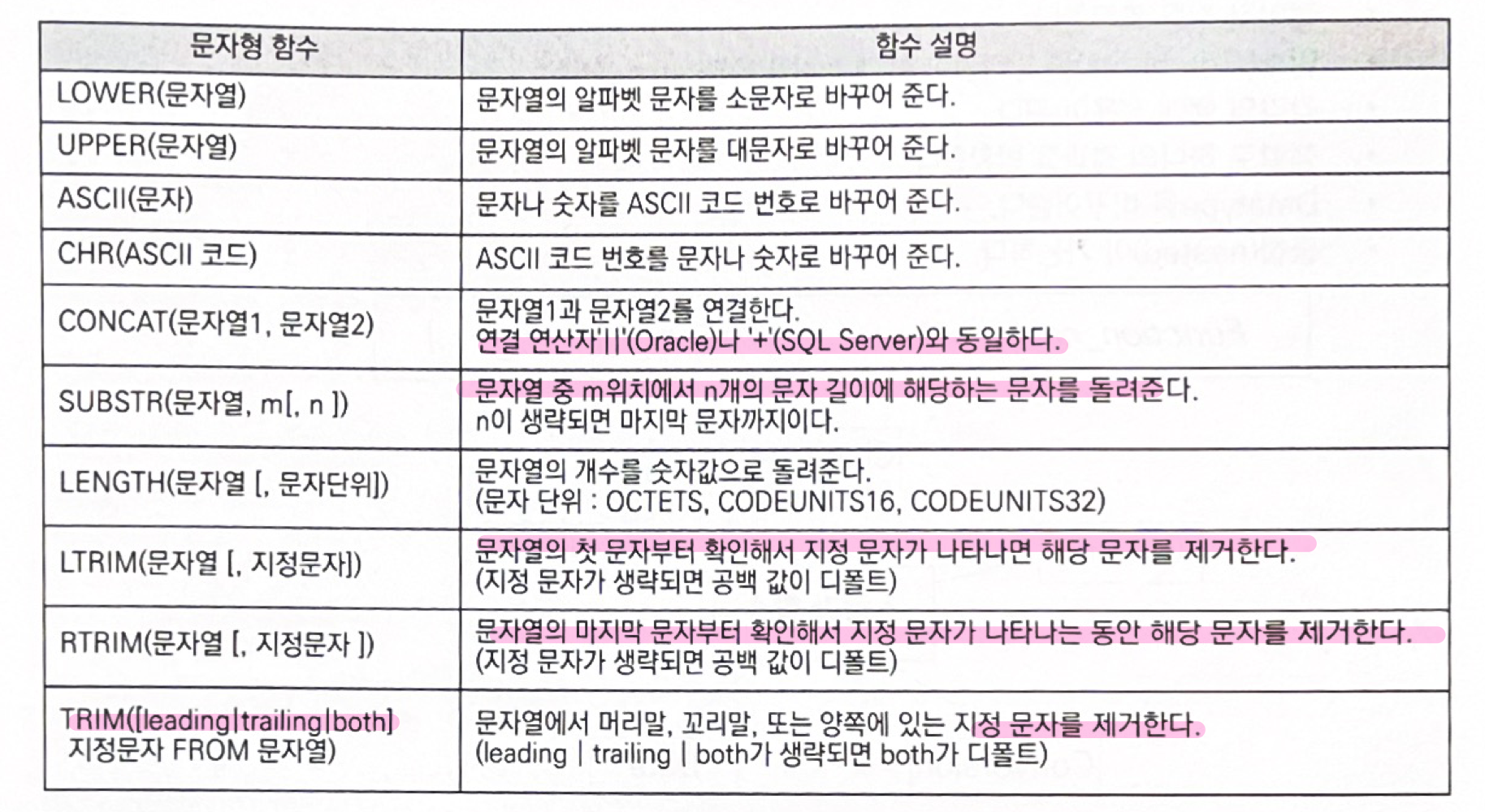

■ 숫자형 함수

■ 날짜 함수


[ 현재 시간 조회 ]
select NOW();
[ 시스템 일자 출력하기 ]
select CURRENT_DATE, CURRENT_TIME, TIMEOFDAY();

select NOW(), CURRENT_TIMESTAMP, TIMESTAMP 'NOW';

[관련 예제] 사원(TB_EMP) 테이블의 입사일자에서 년, 월, 일 데이터 출력
[ TO_CHAR 사용 ]
select emp_name, ENT_DATE,
TO_CHAR(ENT_DATE, 'YYYY') 입사년,
TO_CHAR(ENT_DATE, 'MM') 입사월,
TO_CHAR(ENT_DATE, 'DD') 입사일
from TB_EMP;정수로 나온다.
[ EXTRACT 사용 ]
select EMP_NAME, ENT_DATE,
EXTRACT(year from ENT_DATE) 입사일,
EXTRACT(month from ENT_DATE) 입사월,
extract(day from ENT_DATE) 입사일
from TB_EMP;
날짜에서 연, 월, 일 을 추출하는 방법
-- DATE_PART 사용
select DATE_PART('YEAR', TIMESTAMP '2021-01-24 20:38:40'); # 2021 년
select DATE_PART('YEAR', current_TIMESTAMP); # 현재 연도
-- EXTRACT 사용
select EXTRACT('ISOYEAR' from DATE '2007-03-02'); # 2007년
select EXTRACT('ISOYEAR' from CURRENT_TIMESTAMP); # 현재 연도
-- DATE TRUNC 사용
select DATE_TRUNC('YEAR', TIMESTAMP '2019-03-02 20:38:40'); # 2019-01-01 출력
select DATE_TRUNC('YEAR', CURRENT_TIMESTAMP); # 현재 연도 2022-01-01 출력
여기서 월은 'MONTH' 일은 'DAY' 로 바꾸어주면 된다.
시간 또한 'HOUR', 'MINUTE', 'SECOND' 로 시간, 분, 초를 추출해낼 수 있다.
■ 변환 함수
변환형 함수는 특정 데이터 타입을 다양한 형식으로 출력하고 싶을 때 사용하는 함수이다.
명시적 데이터 유형 변환, 암시적 데이터 유형 변환이 있다.
명시적인 데이터 유형 변환 방법을 사용하는 것이 바람직하다.

TO_CHAR 구문
select EMP_NAME, ENT_DATE,
TO_CHAR(ENT_DATE, 'YYYY') 입사년,
TO_CHAR(ENT_DATE, 'MM') 입사월,
TO_CHAR(ENT_DATE, 'DD') 입사일
from CSLEE.TB_EMP;
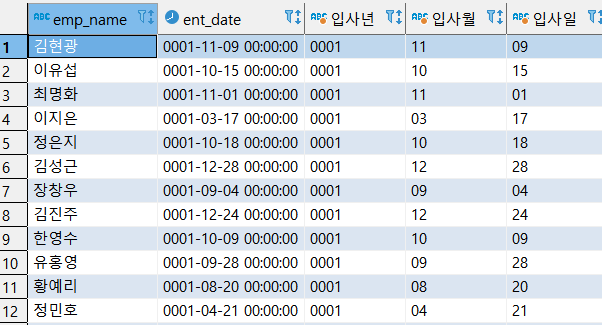
'YYYY', 'MM' 등의 주어진 FORMAT 대로 하는 것을 볼 수 있다.
TO_CHAR 로 했던 데이터를 EXTRACT 로 바꾸어보면 ?
EXTRACT 구문
select EMP_NAME, ENT_DATE,
extract ('YEAR' from ENT_DATE) 입사년,
extract ('MONTH' from ENT_DATE) 입사월,
extract ('DAY' from ENT_DATE) 입사일
from CSLEE.TB_EMP;
변환함수(명시적 데이터 유형 변환) TO_DATE, TO_NUMBER, TO_TIMESTAMP, CAST
-- TO_DATE
select TO_DATE('05 DEC 2000', 'DD MON YYYY'); -- 05 DEC 2000 으로 적어도 2000 DEC 05 로 인식
-- TO_NUMBER
select TO_NUMBER('12,454.8-', '99G999D9S'); -- 뭐지 문자열을 숫자형으로 바꾸어준다.
select TO_TIMESTAMP('05 DEC 2000', 'DD MON YYYY'); -- 잘 인식해서 TIMESTAMP 를 보여준다
예제
select CAST(123.4 as VARCHAR(10))
, CAST('123.5' as NUMERIC)
, CAST(1234.5678 as dec(6,2))
, CAST(CURRENT_TIMESTAMP as DATE)
, TO_CHAR(CURRENT_TIMESTAMP, 'YYYY-MM-DD HH24')
, TO_CHAR(1234.56, 'L9,999.99')
, TO_NUMBER('$12,345', '$99,999')
, TO_DATE('2014/03/01 21:30:18', 'YYYY/MM/DD HH24:MI:SS')
, TO_TIMESTAMP('2014/03/01 21:30:18', 'YYYY/MM/DD HH24:MI:SS');


CASE 표현
CASE 표현은 IF-THEN-ELSE 논리와 유사한 방식으로 표현식을 작성해서 SQL 의 비교 연산 기능을 보완한다.
ANSI-SQL 표준에는 CASE Expression 이라고 표시되어 있는데, 함수와 같은 성격을 가지고 있다.
예제 ) 연봉이 5000만원 이상인 사람들은 연봉을 표시, 이하인 사람들은 5000만원이라고 REVISED_SALARY 컬럼 안에 표시, 직원의 이름을 직원 테이블에서 찾아서 표시한다.
select EMP_NAME,
case when SALARY > 50000000
then SALARY
else 50000000
end as REVIESED_SALARY
from CSLEE.TB_EMP;

예제 2) CSLEE 안의 ORG 테이블에서 ORG_NAME 을 불러오고, ORG_NAME 안의 영업1,2,3 팀은 지사,
경영관리팀은 본사, 나머지는 지점으로 하여 AREA 열 안에 넣어라.
select ORG_NAME,
case ORG_NAME
when '영업1팀' then '지사'
when '영업2팀' then '지사'
when '영업3팀' then '지사'
when '경영관리팀' then '본사'
else '지점'
end as AREA
from CSLEE.TB_ORG;
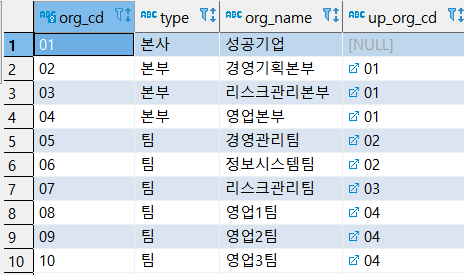
위는 SELECT * FROM ORG_NAME 을 했을 때 나오는 결과.
영업 1팀, 2팀, 3팀 1개씩. 경영관리팀 1개, 나머지 총 6개가 있다.
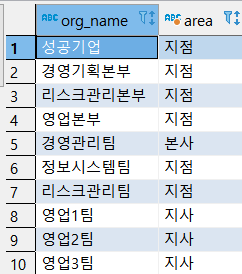
AREA 를 봤을 때 지사 3개, 본사 1개, 지점 6개이므로 결과가 맞게 나온 것을 알 수 있다.
예제 3 ) TB_EMP 에서 EMP_NAME 과 SALARY_GRADE 를 출력한다.
SALARY_GRADE 는 SALARY 가 9000만원 이상이면 'HIGH', 6000만원 이상이면 'MID' , 나머지는 'LOW' 로 출력한다.
select EMP_NAME,
case when SALARY >= 90000000 then 'HIGH'
when SALARY >= 60000000 then 'MID'
else 'LOW'
end as SALARY_GRADE
from CSLEE.TB_EMP;
select EMP_NAME, SALARY from CSLEE.TB_EMP 를 했을 때의 출력
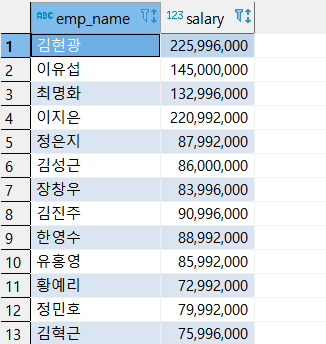
위의 코드를 출력한 결과,
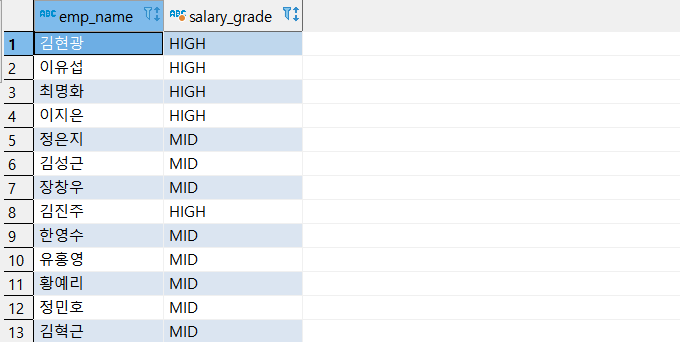
예제 4) EMP_NAME 과 SALARY 를 불러오고, BONUS 칼럼을 만들어서 SALARY 에서 5000만원 이상의 연봉을 받는 사람은 2000만원, 2000만원 이상의 연봉을 받는 사람은 1000만원을 넣는 예제
select EMP_NAME, SALARY,
case when SALARY >= 50000000 then 20000000
when SALARY >= 20000000 then 10000000
else SALARY * 0.5
end as BONUS
from CSLEE.TB_EMP;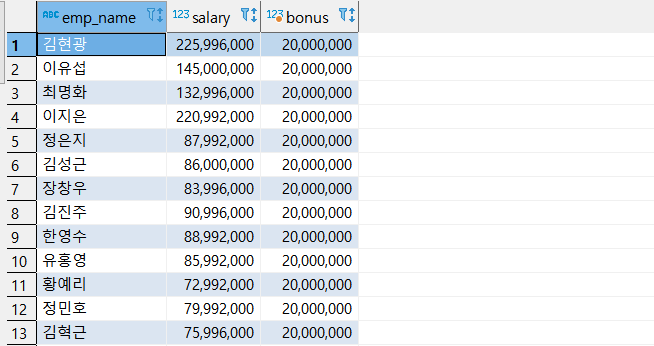
NULL 관련 함수
NULL 값은 아직 정의되지 않은 값으로, 0 또는 공백과는 다르다.
테이블을 생성할 때, NOT NULL 이나 PRIMARY KEY 로 설정되지 않은 모든 데이터 유형은 NULL값을 포함할 수 있다.
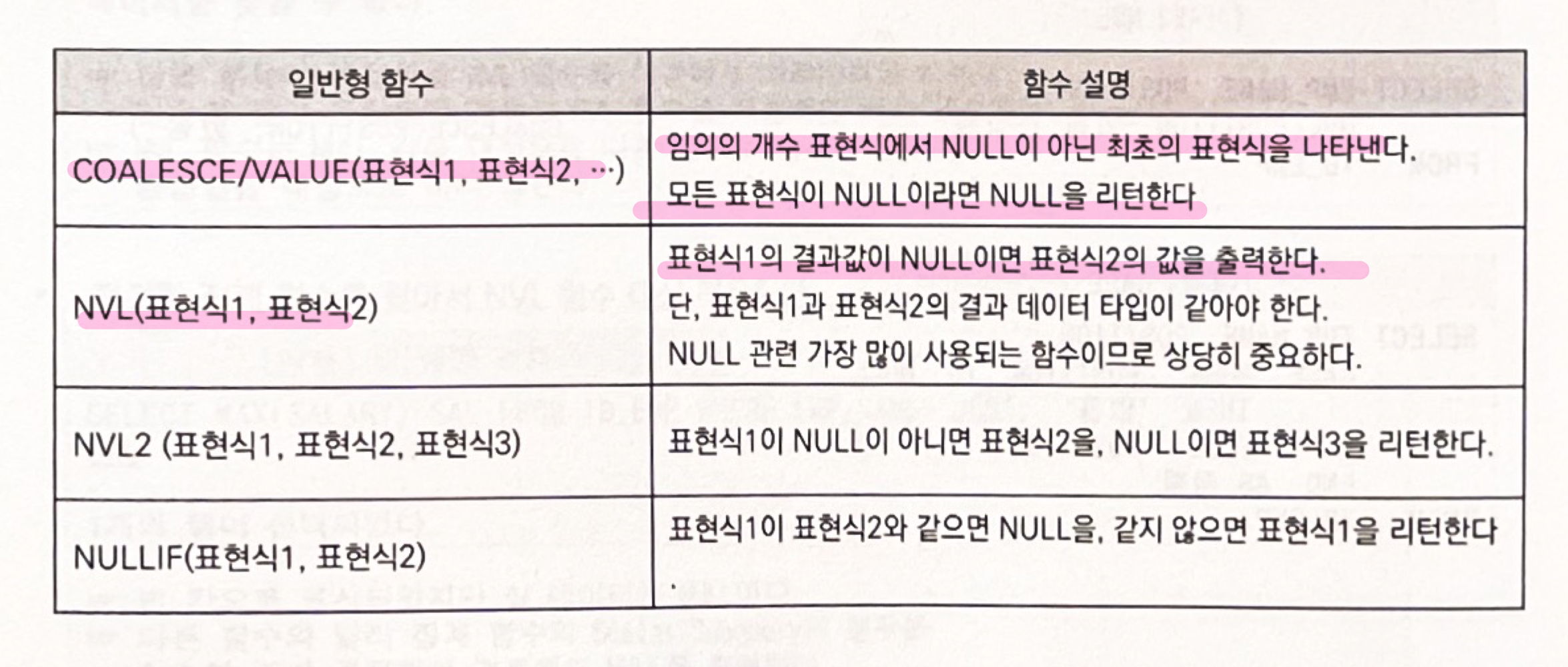
NVL 함수는 NULL 값이 아닌 다른 값을 얻고자 할 때 사용한다.
■ NVL 함수 = COALESCE (postgresql 에 있음)
- NULL 값을 실제값으로 전환한다.
- 데이터 타입은 date , character, number 로 사용되어질 수 있다.
- 데이터형은 일치해야 한다.
우리가 사용하는 postgresql 에는 NVL 함수가 없다.
Oracle 에서는 만나볼 수 있다..
대신 우리에겐 COALESCE 함수가 있다.
COALESCE 함수 예제. NULL 값 -> '없음'
select EMP_NAME, position from CSLEE.TB_EMP 을 사용해서 먼저
NULL 값이 있는 지를 확인해보자.

이제, NVL 함수를 이용해서 NULL 값을 '없음' 으로 바꾸어보자.
select EMP_NAME, position,
COALESCE(position ,'없음')
from CSLEE.TB_EMP;
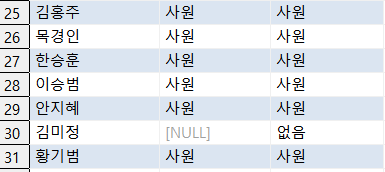
없음 으로 잘 바뀌었다.
오라클에서는 COALESCE 대신 NVL 을 사용하면 되겠다.
■ NULL 과 공집합
조건에 맞는 데이터가 한 건도 없는 경우를 공집합이라고 한다.
이는 NULL 데이터와는 또 다르게 이해를 해야한다.
select EMP_NAME, SALARY
from CSLEE.TB_EMP
where EMP_NAME = '김태진';
김태진 씨는 사원 테이블에 없다.
그러므로 아무것도 출력되지 않을 것이다. (공집합이다)
select coalesce(salary, 0) SAL
from cslee.tb_emp
where emp_name ='김태진';
많은 사람들이 공집합을 COALESCE 함수를 이용해서 처리하려고 하는데,
인수의 값이 공집합인 경우에는 SOALESCE(NVL) 함수를 사용해도 역시 공집합이 출력된다.
이 함수는 NULL 값을 대상으로 다른 값으로 바꾸는 함수이지 공집합을 대상으로 하는 것이 아니다.
그렇다면 적절한 집계함수를 찾아 COALESCE 함수 대신 사용해보자.
SELECT MAX(salary) SAL
FROM cslee.tb_emp
WHERE emp_name='김태진';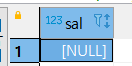
앞과 다르게 NULL 값이 공집합임에도 불구하고 출력되었다.
NULL 값이라고 표현되었다.
다른 함수와 달리 집계함수와 Scaler Subquery 같은 경우는 인수의 값이 공집합인 경우에도
NULL 로 출력함에 유의하자.
SELECT coalesce(MAX(salary), 9999) SAL
FROM cslee.tb_emp
WHERE emp_name='김태진';
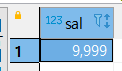
MAX() 를 사용하여 값에 NULL 출력을 만든 후, COALESCE 함수를 사용하면
정상적으로 NULL 값 대신에 원하는 값이 채워진다.
Review
SQL 함수에 대해서 알아보았다.
SQL 함수는 어떤 로직을 실행하고 결과값을 출력하는, 다른 프로그래밍 언어와 마찬가지로 함수이다.
SQL 함수에는 단일행과 복수행 함수가 있다.
스칼라 함수에는 문자형 , 숫자형, 집계형 , 날짜형, 변환함수, NULL 관련 함수가 있는데,
우리는 이걸 다 알아보고 실습했다.
어렵지는 않지만 .. 외우기엔 힘들 것 같은 ..느낌이다 ..
※ 저의 모든 데이터 분석 자료는 모두 공공 빅데이터 청년 인턴 교재들을 참고합니다.