[Data/Data Analysis] Kaggle : Spaceship Titanic
Spaceship Titanic
Predict which passengers are transported to an alternate dimension

https://www.kaggle.com/competitions/spaceship-titanic/overview
Spaceship Titanic | Kaggle
www.kaggle.com
다른 차원으로 이동된 승객들을 예측하는 모델을 만들어보자!
어떤 승객들이 이상 현상에 의해서 다른 차원으로 이동되었는 지 예측하는 재밌는 스토리 ..
데이터 살펴보기
Data Dictionary
- PassengerId : 승객 ID
- HomePlanet : 출발 행성(거주지)
- CryoSleep : 취침 방식 여부
- Cabin : 객실 종류 및 번호 (port : 좌현, starboard : 우현)
- Destination : 목적지
- Age : 승객의 나이
- VIP : 승객의 VIP 서비스 유무
- RoomService, FoodCourt, ShoppingMall, Spa, VRDeck : 승객이 해당 서비스에 대해 지불한 금액
- Name : 이름
- Transported : 이동 여부
우리의 Target 변수는 Transported 이다.
변수들에 따라 누가 이동하고 이동하지 않는 지를 예측해야 한다.
필요한 라이브러리들을 import 해준다.
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import os
from scipy import stats
import missingno as msno
plt.style.use('seaborn')
import warnings
warnings.filterwarnings("ignore")
mpl.rcParams['axes.unicode_minus'] = False
%matplotlib inlinedf_train = pd.read_csv('./train.csv')
print(df_train.shape)
df_train.head()
df_test = pd.read_csv('./test.csv')
print(df_test.shape)
df_test.head()
train, test데이터를 불러왔다.
df_train.info()
# train 데이터의 missing value
msno.matrix(df_train, figsize = (12,5))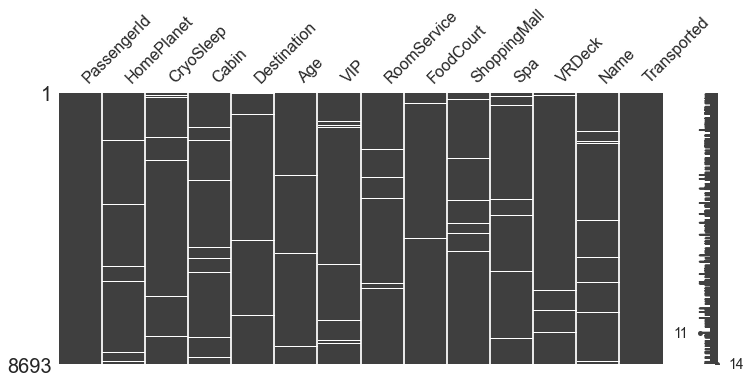
df_train.isna().sum()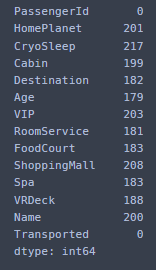
곳곳이 숭숭 뚫려있다.
Null 값들은 나중에 처리해주어야 할 것 같다.
df_test.info()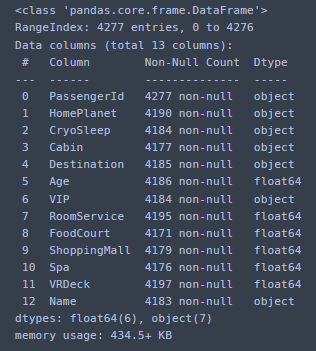
df_test.isna().sum()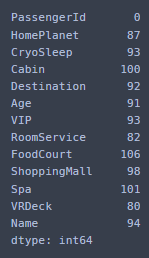
test도 마찬가지.
수치형 변수들을 describe 로 살펴본다
df_train.describe()
0세는 신생아인가 ..
기타 편의시설은 거의 0인 것을 확인할 수 있다. 이용이 거의 없다는 거겠지
그러나 max값은 상당히 큰 것을 확인할 수 있다.
범주형 데이터 또한 확인해보자.
df_train.describe(include=['O']) #범주형 데이터 확인
passengerID는 고유ID이고,
HomePlanet, Destination은 3개, CryoSleep,VIP 은 2개의 범주밖에 없다.
Name 은 별로 필요 없는 변수일 것 같고,
Cabin 은 3개로 나누어서 확인하면 될 것 같다.
df_test.describe()
df_test.describe(include=['O']) #범주형 데이터 확인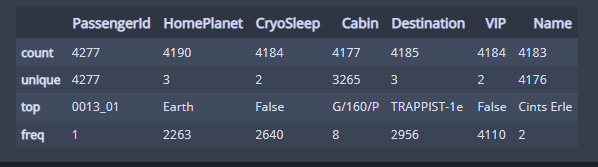
test데이터도 별 다를 것이 없다.
Histogram을 그려서 수치형변수들의 자료를 시각화하여 확인해보자.
df_train.hist(figsize = (10,9))
plt.show()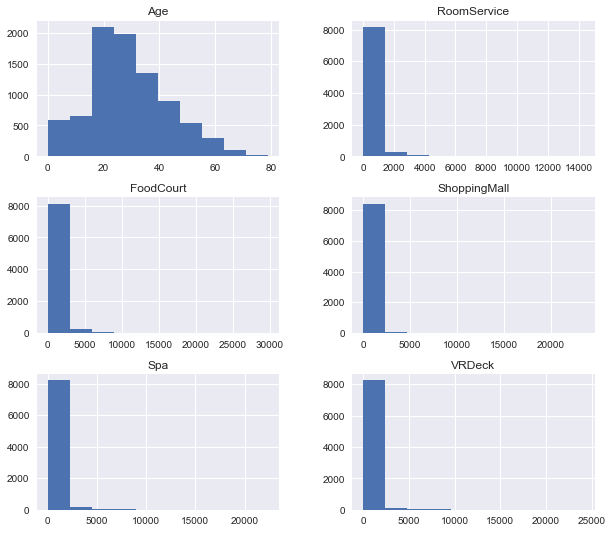
나이는 2-40대가 가장 많다.
다른 서비스들 (룸서비스, 푸드코트, 스파, 쇼핑몰 ,VRDeck) 은 거의 0에 분포를 하는 것을 확인할 수 있다.
거의 사용이 없다고 보면 되겠다.
전처리
결측치를 처리해보자.
결측치들의 비중은 그렇게 많지 않았다.
# 결측치 처리
df_train['CryoSleep'] = df_train['CryoSleep'].fillna(0) # 최빈값인 0으로 대체
df_train['VIP'] = df_train['VIP'].fillna(0) # 최빈값인 0으로 대체 -> 둘 다 Bull형임
df_train['Cabin'] = df_train['Cabin'].fillna(df_train['Cabin'].mode()[0])
df_train['HomePlanet'] = df_train['HomePlanet'].fillna(df_train['HomePlanet'].mode()[0])
df_train['Destination'] = df_train['Destination'].fillna(df_train['Destination'].mode()[0])
df_train['ShoppingMall'] = df_train['ShoppingMall'].fillna(df_train['ShoppingMall'].median())
df_train['VRDeck'] = df_train['VRDeck'].fillna(df_train['VRDeck'].median())
df_train['FoodCourt'] = df_train['FoodCourt'].fillna(df_train['FoodCourt'].median())
df_train['Spa'] = df_train['Spa'].fillna(df_train['Spa'].median())
df_train['RoomService'] = df_train['RoomService'].fillna(df_train['RoomService'].median())
df_train['Age'] = df_train['Age'].fillna(df_train['Age'].median())CryoSleep, VIP, HomePlanet, Cabin, Destination 등 bool형이거나 범주형인 변수들은 최빈값으로 전처리해주었다.
그 외 수치형 데이터는 예외값에 영향을 거의 받지 않는 중앙값으로 대체해주었다.
최빈값들은 0인데 Max값은 무척 컸으므로 평균을 쓰기에는 무리가 있었다.
/로 나누어진 Cabin 데이터를 분할해주었다.
# Cabin 분할
cab = df_train['Cabin'].apply(lambda x:x.split("/"))
df_train['Cab_1'] = cab.apply(lambda x: x[0])
df_train['Cab_3'] = cab.apply(lambda x: x[2])
df_train['Cab_2'] = cab.apply(lambda x: float(x[1]))
df_train
# / 로 나누어진 데이터를 분할했다. 영문자, 숫자로 분할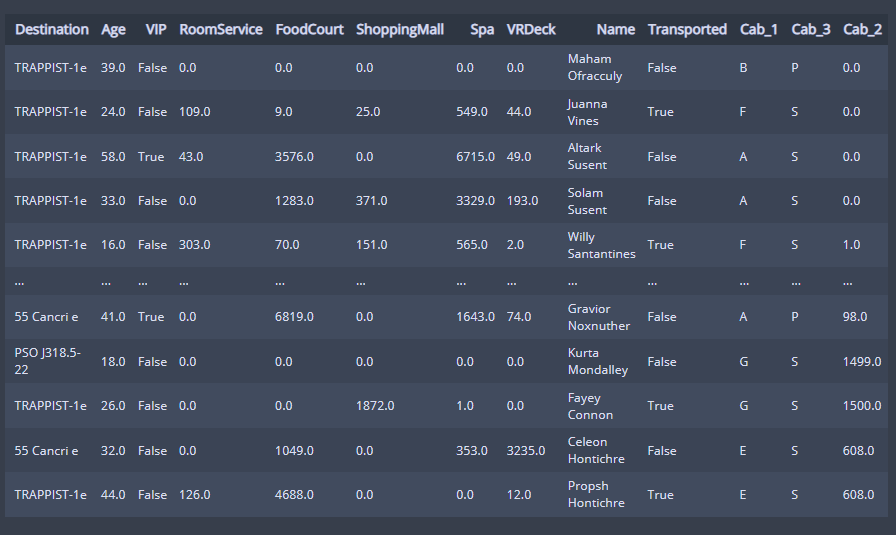
Cabin 1 2 3 칼럼들이 만들어져 각각 첫번째 두번째 세번째 자리들의 값들이 들어갔다.
나머지 필요없는 column 들은 drop 해준다.
# 필요없는 column drop
df_train.drop(['PassengerId', "Name", 'Cabin'], axis= 1, inplace = True)
# cabin은 위에서 분할해서 사용하기 때문에 drop, ID와 Name은 도착여부랑 상관없기 때문에 drop
분석을 용이하게 하기 위해 VIP 와 CryoSleep 을 int 형으로 타입을 바꾸어준다..
# bool형을 int로 변경
df_train['VIP'] = df_train['VIP'].astype(int)
df_train['CryoSleep'] = df_train['CryoSleep'].astype(int)# 결측치 확인
df_train.isna().sum()
결측치가 다 대체된것을 볼 수 있다.
EDA
VIP
df_train[['VIP', 'Transported']].groupby(['VIP'], as_index = False).mean().sort_values(by='Transported'VIP와 Transported 의 관계를 알아본다.
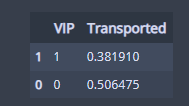
비율을 확인하였을 때 VIP가 아닌 아닌 사람들은 반절 정도가 이동했고,
VIP 인 사람들은 38% 정도 이동했다.
arrived = df_train[df_train['Transported'] == 1]['VIP'].value_counts()
not_arrived = df_train[df_train['Transported'] == 0]['VIP'].value_counts()
df = pd.DataFrame([arrived , not_arrived])
df. index = ['arrived', 'not_arrived']
df. plot(kind = 'bar', stacked = True, figsize = (6,4))
plt.title("VIP")
plt.show()
그러나 전체적인 비율로 확인했을 때,
VIP인 사람들의 비율 자체가 무척 적기 때문에 유의성이 보이지 않는다.
시각화해서 살펴보았을 때 이동하지 않은 사람들 중 VIP의 비율이 조금 더 높다.
CryoSleep
df_train[['CryoSleep', 'Transported']].groupby(['CryoSleep'], as_index = False).mean().sort_values(by = 'Transported')
Cryosleep 은 대충 취침방식이긴 하지만 제대로 뜻을 살펴보니
cryosleep (uncountable)
- (science fiction) A deep sleep during which the body is stored at very cold temperature, to preserve it; cryogenic sleep.

냉동보존(?) 된 채로 자고 있는 사람들..
냉동수면 여부인 것 같다.
아무래도 Spaceship 안이라서 .. 냉동수면이 필요한가보다.
냉동수면을 한 사람들의 82% 정도가 이동했다.
arrived = df_train[df_train['Transported'] == 1]['CryoSleep']. value_counts()
not_arrived = df_train[df_train['Transported'] == 0]['CryoSleep'].value_counts()
df = pd.DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df.plot(kind = 'bar', stacked = False, figsize = (6,4))
plt.title("CryoSleep")
plt.show()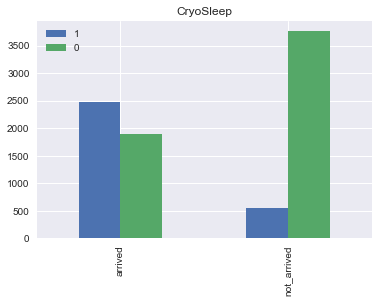
전체적인 비율을 봤을 때도 이동하지 않은 사람들의 비율 중 Cryosleep 을 하고 있는 사람들의 비중이
압도적으로 높다.
상관성이 높을 것이라고 생각된다.
Homeplanet
df_train[['HomePlanet', 'Transported']].groupby(['HomePlanet'], as_index = False).mean().sort_values(by='Transported')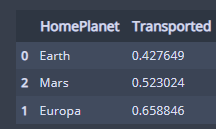
비율로 보았을 때 Europa 행성이 고향인 사람들의 65%정도가 이동되었다.
근데 다 많이 이동됐는데 ..?
Europa는 목성의 위성이다.
arrived = df_train[df_train['Transported'] == 1]['HomePlanet']. value_counts()
not_arrived = df_train[df_train['Transported'] == 0]['HomePlanet']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df.index = ['arrived','not_arrived']
df.plot(kind= 'bar',stacked= False , figsize= (6,4))
plt.title('HomePlanet')
plt. show()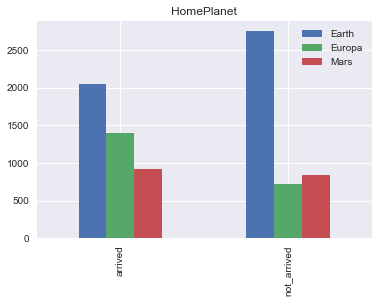
그러나 이동하지 않은 사람들의 비율로만 보았을 때에는 지구인의 비율이 압도적으로 높았다 .
Europa, Mars 행성은 탑승객 자체가 적은 것 같다.
Destination
df_train[['Destination', 'Transported']].groupby(['Destination'], as_index = False).mean().sort_values(by = 'Transported')
TRAPPIST-1e 도착지인 사람들의 47%가 이동되었고,
PSO J318.5-22 가 도착지인 사람들은 50% 가 이동되었고,
55 Cancrie 가 도착지인 사람들 중 61%가 이동되었다.
arrived = df_train[df_train['Transported'] == 1]['Destination'].value_counts()
not_arrived = df_train[df_train['Transported']==0]['Destination'].value_counts()
df = pd.DataFrame([arrived, not_arrived])
df.index = ['arrived', 'not_arrived']
df.plot(kind = 'bar', stacked = False, figsize = (8,4))
plt.title("Destination")
plt.show()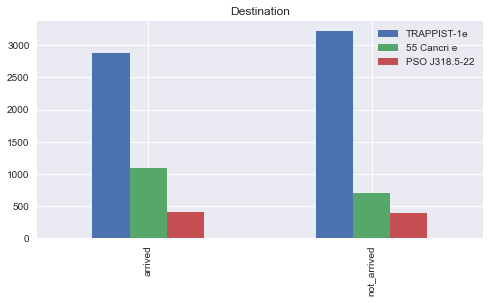
TRAPPIST-1e는 그냥 사람이 많은 것 같다.
도착과 도착하지 못한 사람들의 비율이 비슷한 걸 보면 그닥 상관성은 없는 것 같다.
Age
df_train.loc[(df_train['Age'] >= 0) & (df_train['Age'] < 10), 'Age'] = 0
df_train.loc[(df_train['Age'] >= 10) & (df_train['Age'] < 20), 'Age'] = 10
df_train.loc[(df_train['Age'] >= 20) & (df_train['Age'] < 30), 'Age'] = 20
df_train.loc[(df_train['Age'] >= 30) & (df_train['Age'] < 40), 'Age'] = 30
df_train.loc[(df_train['Age'] >= 40) & (df_train['Age'] < 50), 'Age'] = 40
df_train.loc[(df_train['Age'] >= 50) & (df_train['Age'] < 60), 'Age'] = 50
df_train.loc[(df_train['Age'] >= 60) & (df_train['Age'] < 70), 'Age'] = 60
df_train.loc[(df_train['Age'] >= 70) & (df_train['Age'] < 80), 'Age'] = 70나이대별로 착착 나눠주고
Arrived = df_train[df_train['Transported'] == 1]['Age'].value_counts()
Not_Arrived = df_train[df_train['Transported'] == 0 ]['Age'].value_counts()
df = pd.DataFrame([Arrived, Not_Arrived])
df. index = ['Arrived', 'Not_Arrived']
df.plot(kind = 'bar', stacked = False, figsize = (8,6)).legend (loc = 'lower center')
plt.title("Age")
plt.show()마찬가지로 이동한 사람들과 이동하지 않은 사람들을 나누어서 bar plot 으로 시각화시켜주었다.
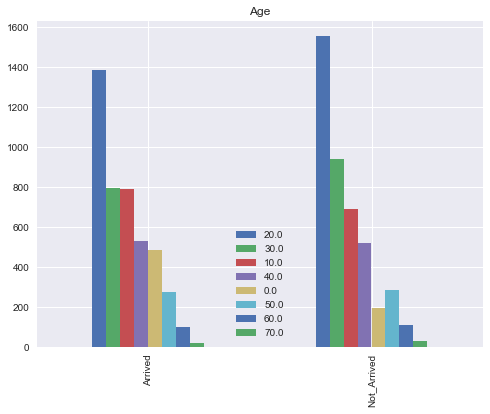
탑승객이 젤 많았던 2-30대가 가장 많이 이동되었고,
0세는 거의 도착한 비율이 높았다. 30대는 이동된 비율이 더 많다.
나머지는 거의 비슷비슷한 걸 보아서 크게 유의한 것 같아 보이지는 않는다.
Cabin
arrived = df_train[df_train['Transported'] == 1]['Cab_1']. value_counts()
not_arrived = df_train[df_train['Transported'] == 0]['Cab_1']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df. plot(kind= 'bar',stacked= False , figsize= (8,6))
plt.title('Cab_1')
plt. show()
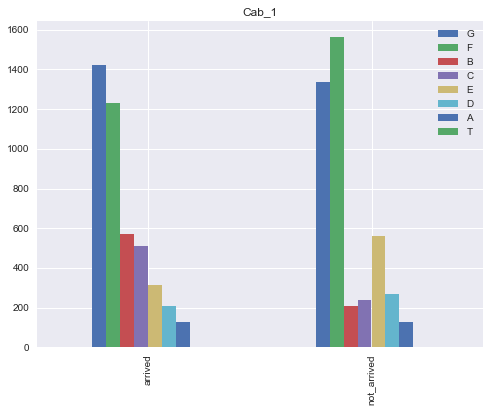
Cab_1 은 맨 앞쪽 알파벳에 대한 변수였다.
F로 시작하는 객실이 많이 이동된 것을 볼 수 있다.
그리고 E로 시작하는 객실 또한 많이 이동된 것을 볼 수 있다.
나머지는 비슷하나 B,C는 이동하지 않은 비율에 비해 두 배 정도 많이 이동한 비율을 보여준다.
arrived = df_train[df_train['Transported'] == 1]['Cab_3']. value_counts()
not_arrived = df_train[df_train['Transported'] == 0]['Cab_3']. value_counts()
df = pd. DataFrame([arrived, not_arrived])
df. index = ['arrived','not_arrived']
df. plot(kind= 'bar',stacked= False , figsize= (8,5))
plt.title('Cab_3')
plt. show()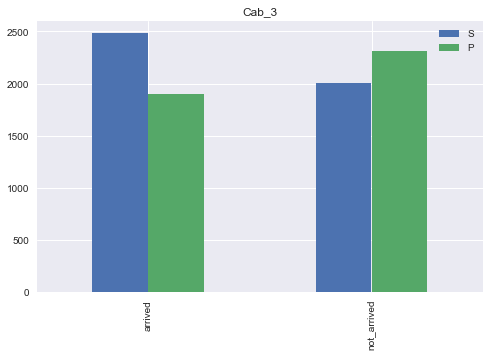
세번째 알파벳은 2개로 나뉘는 범주형이었다.
S가 P보다 더 많이 이동하지 않음을 확인할 수 있으나 엄청나게 큰 차이는 아닌 것 같다.
마지막으로 상관계수를 비교해주자.
plt.figure(figsize = (16, 12))
x = sns.heatmap(df_train.corr(), cmap = 'Blues', linewidths = '0.1',annot = True)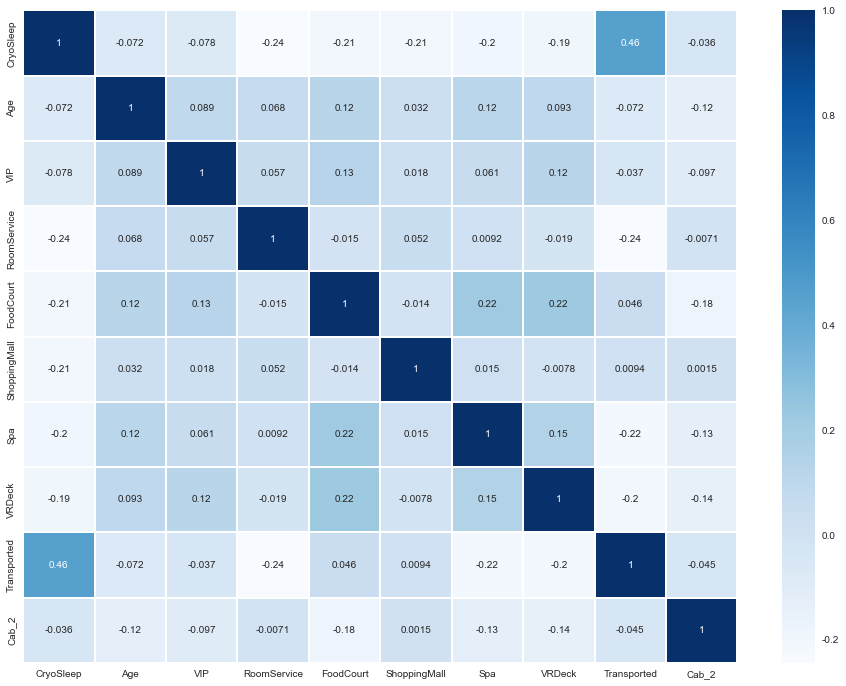
우리가 위에서 확인한 대로 Cryosleep 이 확실히 상관관계가 다른 변수들보다 있다는 것을
확인했으나, 0.48정도로 그렇게 큰 상관성을 보이지는 않는다.
Feature Engineering
사실 이미 위에서 EDA를 할 때 어느정도 Feature Engineering 을 하기는 했다.
범주형 변수들을 다시 One-Hot Encoding 하여 분석에 용이하게 만들어준 후,
모델 안에 넣을 encoding train data를 만들어주자.
# OneHotEncoding 을 사용하여 범주형을 수치형으로 변환
input_data = df_train.drop(['Transported'], axis=1)
encoding_train_data = pd.get_dummies(input_data)
encoding_train_data모델 안에 넣을 데이터이므로, Transported 는 제외하고 input에 넣어주었다.
encoding_train_data.columnsIndex(['CryoSleep', 'Age', 'VIP', 'RoomService', 'FoodCourt', 'ShoppingMall',
'Spa', 'VRDeck', 'Cab_2', 'HomePlanet_Earth', 'HomePlanet_Europa',
'HomePlanet_Mars', 'Destination_55 Cancri e',
'Destination_PSO J318.5-22', 'Destination_TRAPPIST-1e', 'Cab_1_A',
'Cab_1_B', 'Cab_1_C', 'Cab_1_D', 'Cab_1_E', 'Cab_1_F', 'Cab_1_G',
'Cab_1_T', 'Cab_3_P', 'Cab_3_S'],
dtype='object')
이제 남은 데이터들을 추가적으로 확인해주자.
pairplot을 그리자..
# 추가 데이터 확인
analysis = pd.merge(encoding_train_data, df_train['Transported'], left_index = True, right_index = True )
sns.pairplot(analysis[['CryoSleep','Age','VIP','RoomService','FoodCourt','ShoppingMall','Transported']]
,hue = 'Transported', palette='husl', markers = ['o','s',])
plt.show()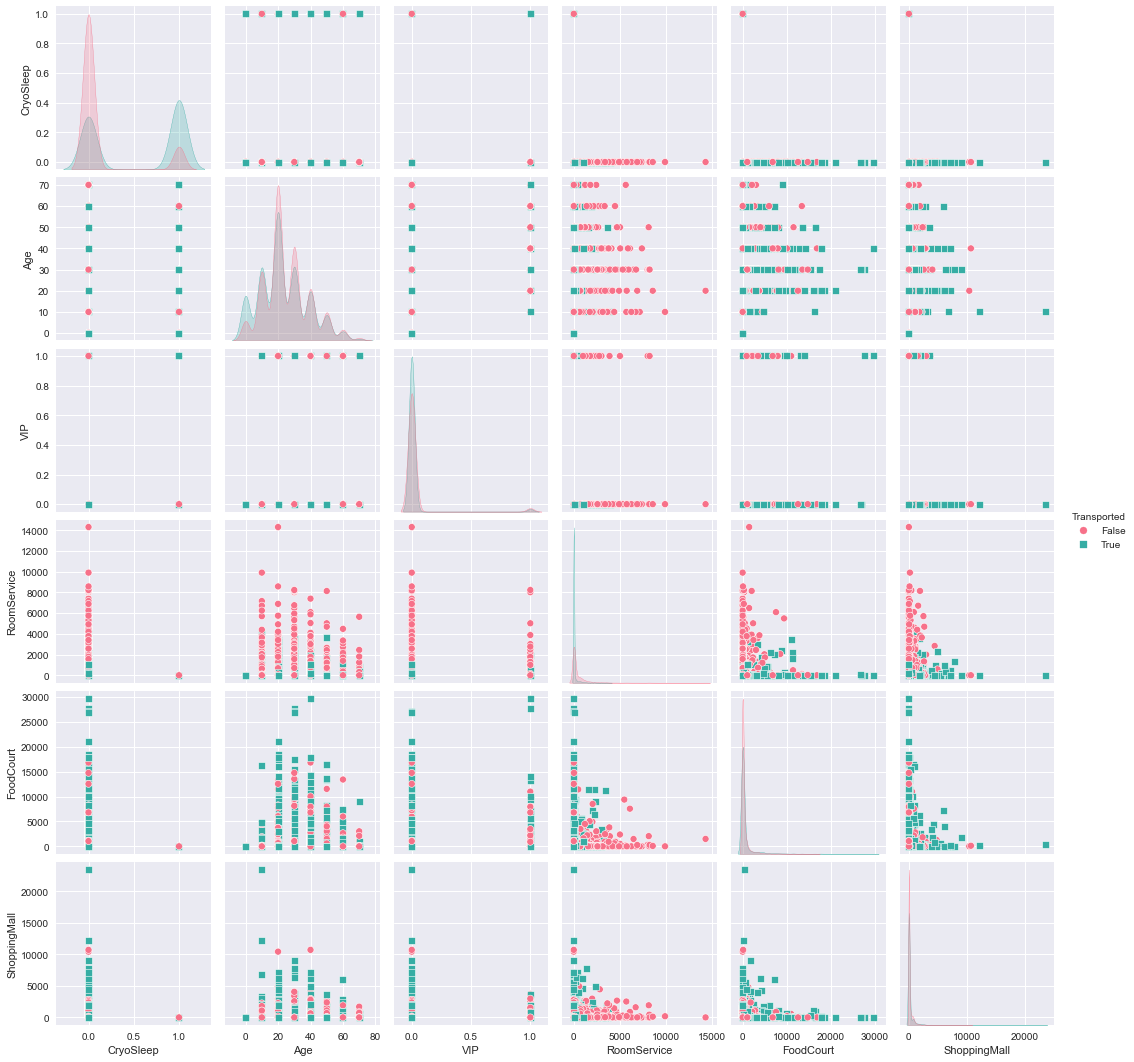
CryoSleep이 0일수록 Transported 차원이동되지 않았다.
CryoSleep을 안한 사람일수록 차원이동을 하지 않았다는 것을 확인할 수 있다.
나머지분포는 뭐 비슷 ..
sns.pairplot(analysis[['Spa', 'VRDeck', 'Destination_55 Cancri e', 'Destination_TRAPPIST-1e', 'Destination_PSO J318.5-22', 'Transported']],hue='Transported', palette='husl', markers=['o','s'])
plt.show()
Destination 이 55 Cancri e 가 아닐수록 차원이동이 되지 않았다.
Destination 이 TRAPPIST - 1e 일수록 차원이동이 되지 않았다.
나머지 분포는 뭐 비슷 ..
sns.pairplot(analysis[['HomePlanet_Earth', 'HomePlanet_Europa', 'HomePlanet_Mars', 'Cab_2',
'Transported']],hue = 'Transported',palette='husl',markers = ['o','s'])
plt.show()
HomePlanet 이 Earth(지구)일수록 차원이동이 되지 않았다.
Europa 이 아닐수록 차원이동이 되지 않았다.
화성은 비슷한 것 같다.
나머지도 뭐 비슷비슷한 것 같다.
sns.pairplot(analysis[['Cab_1_F',"Cab_1_G",'Cab_1_T',"Cab_3_P",'Cab_3_S',"Transported"]],
hue = 'Transported', palette = 'husl', markers = ['o','s'])
plt.show()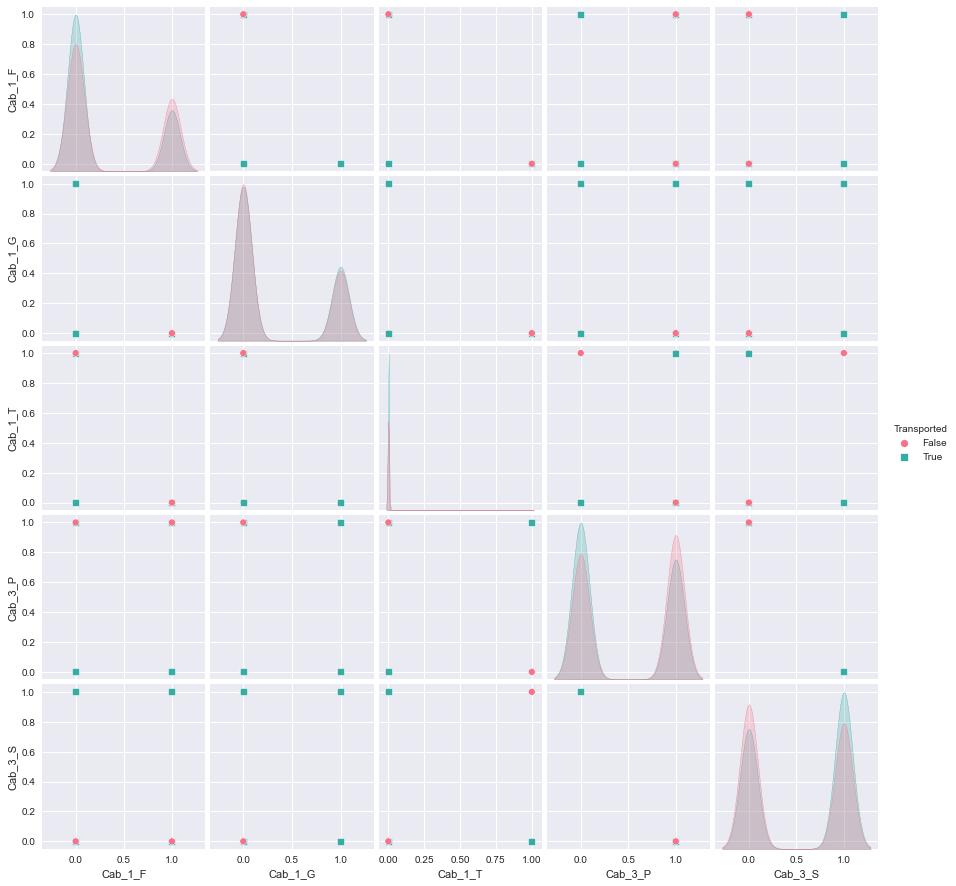
분포가 비슷비슷..한 것 같으나
Cabin 3번째 글자가 P일수록 차원이동이 되지 않고,
S일수록 차원이동이 된 것을 알 수 있다.
Model 적용
Random Forest Classifier 을 사용해서 Model 을 적용할 것이다.
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV필요한 라이브러리들을 import 해준다.
정확도를 높이기 위해 PCA를 적용해준다.
y_target = df_train['Transported']
x_data = encoding_train_data.drop(['Cab_1_A','Cab_1_G','Cab_1_T','Cab_1_D','Cab_1_C','VIP',
'HomePlanet_Mars','Destination_PSO J318.5-22'],axis=1)
pca = PCA(n_components = 10)
pca.fit(x_data)
pca_train_data = pca.transform(x_data)
pca_train_data
pca_cols = []
for i in range(0,10) :
x = 'pca_col' + str(i)
pca_cols.append(x)
pca_cols
pca_df = pd.DataFrame(pca_train_data, columns = pca_cols)
pca_df이전 단계에서 유사한 feature을 drop 했으나 대다수 유사한 형태의 feature가 있었기 때문에
feature 를 줄이고 과적합 방지를 위하여 PCA를 사용했다.
10개가 적당하다는 결론이 나와 10개의 주성분으로 PCA 진행
x_train, x_test, y_train, y_test = train_test_split(pca_df, y_target, test_size = 0.2, random_state= 0)params = { 'n_estimators' : [50,100,200,300,400],
'max_depth' : [4,6,8,10,12,16],
'min_samples_leaf' : [4,8,12,16,20], # 과적합제어
'min_samples_split' : [4,8,12,16,20] # 과적합 제어
}
grid_re_clf = RandomForestClassifier(random_state = 5, n_jobs = -1)
grid_cv = GridSearchCV(grid_re_clf, param_grid = params, cv = 5, n_jobs = -1)
grid_cv.fit(x_train,y_train)
print("최적 하이퍼 파라미터 : ",grid_cv.best_params_)
print("최고 예측 정확도 : {:.4f}".format(grid_cv.best_score_))최적 하이퍼 파라미터 : {'max_depth': 10, 'min_samples_leaf': 16, 'min_samples_split': 4, 'n_estimators': 300}
최고 예측 정확도 : 0.7972GridSearch로 최적파라미터를 얻어냈다.
이 파라미터값을 넣어 모델을 학습시켜준다.
- n_estimators = 모델에서 사용할 트리의 개수
- max_depth = 최대 깊이
- min_samples_split = 내부 노드 분할에 필요한 최소 샘플 수
- min_samples_leaf = 리프 노드에 있어야 할 최소 샘플 수
# 모델 학습
pca_model = RandomForestClassifier(n_estimators = 100, random_state = 5,
max_depth = 10, min_samples_leaf = 16,
min_samples_split = 4, oob_score = True)
pca_model.fit(x_train,y_train)
pred = pca_model.predict(x_test)
# 평가
print("훈련 세트 정확도 : {:.3f}".format(pca_model.score(x_train, y_train)) )
print("테스트 세트 정확도 : {:.3f}".format(pca_model.score(x_test, y_test)) )
print("OOB 샘플의 정확도 : {:.3f}".format(pca_model.oob_score_) )훈련 세트 정확도 : 0.832
테스트 세트 정확도 : 0.792
OOB 샘플의 정확도 : 0.79279% 정도의 정확도를 보인다.
이번에는 pca를 진행하지 않은 data 로 모델을 학습시켜보자.
y_target = df_train['Transported']
x_data = encoding_train_data.drop(['Cab_1_A', 'Cab_1_G', 'Cab_1_T', 'Cab_1_D', 'Cab_1_C', 'VIP', 'HomePlanet_Mars', 'Destination_PSO J318.5-22'], axis = 1)
x_train, x_test, y_train, y_test = train_test_split(x_data, y_target, test_size = 0.15, random_state = 0)
params = { 'n_estimators' : [50, 100, 200, 300, 400],
'max_depth' : [4, 6, 8, 10, 12, 16],
'min_samples_leaf' : [4, 8, 12, 16, 20], #과적합 제어
'min_samples_split' : [4, 8, 12, 16, 20] #과적합 제어
}
grid_re_clf = RandomForestClassifier(random_state = 5, n_jobs = -1)
grid_cv = GridSearchCV(grid_re_clf, param_grid = params, cv = 5, n_jobs = -1)
grid_cv.fit(x_train, y_train)
print('최적 하이퍼 파라미터: ', grid_cv.best_params_)
print('최고 예측 정확도: {:.4f}'.format(grid_cv.best_score_))# 모델 학습
model = RandomForestClassifier(n_estimators = 200, random_state=5,
max_depth = 16, min_samples_leaf = 8,
min_samples_split = 4, oob_score=True)
model.fit(x_train, y_train)
pred = model.predict(x_test)
# 평가
print("훈련 세트 정확도: {:.3f}".format(model.score(x_train, y_train)) )
print("테스트 세트 정확도: {:.3f}".format(model.score(x_test, y_test)) )
print("OOB 샘플의 정확도: {:.3f}".format(model.oob_score_) )훈련 세트 정확도: 0.848
테스트 세트 정확도: 0.806
OOB 샘플의 정확도: 0.802위에서 나온 최적파라미터값을 넣어주고 모델을 돌리니 80% 정도로 정확도가 조금 올랐다.
# feature importance
ftr_importances_values = model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values, index = x_train.columns)
ftr_sort = ftr_importances.sort_values(ascending = False)
plt.figure(figsize = (12,10))
plt.title("Feature Importances")
sns.barplot(x=ftr_sort, y=ftr_sort.index)
plt.show()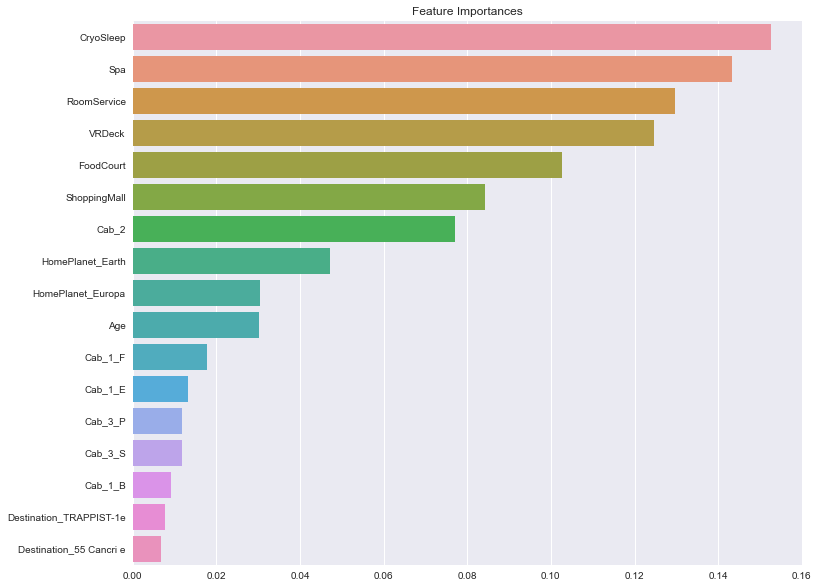
변수 중요도를 살펴보니 역시나 CryoSleep 이 가장 중요한 변수였고,
그 다음이 Spa, Roomservice .. 등등 이었다.
Test data 적용
동일한 방법을 test data 에도 적용시켜준다.
df_test.isna().sum() #데이터 결측치 확인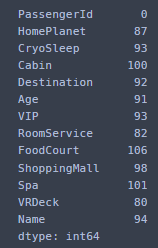
# 결측치 처리
df_test['CryoSleep'] = df_test['CryoSleep'].fillna(0)
df_test['VIP'] = df_test['VIP'].fillna(0)
df_test['Cabin'] = df_test['Cabin'].fillna(df_test['Cabin'].mode()[0])
df_test['HomePlanet'] = df_test['HomePlanet'].fillna(df_test['HomePlanet'].mode()[0])
df_test['Destination'] = df_test['Destination'].fillna(df_test['Destination'].mode()[0])
df_test['ShoppingMall'] = df_test['ShoppingMall'].fillna(df_test['ShoppingMall'].median())
df_test['VRDeck'] = df_test['VRDeck'].fillna(df_test['VRDeck'].median())
df_test['FoodCourt'] = df_test['FoodCourt'].fillna(df_test['FoodCourt'].median())
df_test['Spa'] = df_test['Spa'].fillna(df_test['Spa'].median())
df_test['RoomService'] = df_test['RoomService'].fillna(df_test['RoomService'].median())
df_test['Age'] = df_test['Age'].fillna(df_test['Age'].median())# Cabin 분할
cab = df_test["Cabin"].apply(lambda x: x.split("/"))
df_test["Cab_1"] = cab.apply(lambda x: x[0])
df_test["Cab_3"] = cab.apply(lambda x: x[2])
df_test["Cab_2"] = cab.apply(lambda x: float(x[1]))#필요 없는 column drop
df_test.drop(['PassengerId', 'Name', 'Cabin'], axis = 1, inplace = True)# bool형 int로 변경
df_test["VIP"] = df_test["VIP"].astype(int)
df_test["CryoSleep"] = df_test["CryoSleep"].astype(int)encoding_test_data = pd.get_dummies(df_test)
test_x_data = encoding_test_data.drop(['Cab_1_A', 'Cab_1_G', 'Cab_1_T', 'Cab_1_D', 'Cab_1_C', 'VIP', 'HomePlanet_Mars', 'Destination_PSO J318.5-22'], axis = 1)pca = PCA(n_components = 10)
pca.fit(encoding_test_data)
pca_test_data = pca.transform(encoding_test_data)
pca_cols = []
for i in range(0, 10) :
x = 'pca_col' + str(i)
pca_cols.append(x)
pca_df = pd.DataFrame(pca_test_data, columns = pca_cols)
pca_rf_pred = pca_model.predict(pca_df)
pca_rf_pred
sample_submission = pd.read_csv('./sample_submission.csv')
sample_submission['Transported'] = pca_rf_pred
sample_submission.to_csv('submission.csv',index = False)
sample_submission.head()PCA 한 데이터를 제출하고,
rf_predict = model.predict(test_x_data)
sample_submission = pd.read_csv('./sample_submission.csv')
sample_submission['Transported'] = rf_predict
sample_submission.to_csv('CKH_submission_2.csv',index = False)
sample_submission.head()PCA를 사용하지 않은 데이터도 제출.
PCA한 것보다 안 한 게 더 높은 스코어를 받았다고 ..
끝
도움 받은 분들 ( 필사 원본 )
이 게시물을 그대로 참조하여 쓴 게시물입니다.
https://velog.io/@ckh0824/Spaceship-Titanic-kaggle#1-vip
Spaceship Titanic - kaggle
1. 필요 라이브러리 import 가끔 출력 되는 에러 메세지 출력을 없애기 위한 코드입니다. 2. 데이터 확인 Data Dictionary PassengerId : 승객 ID HomePlanet : 출발 행성(거주지) CryoSleep - 취침 방식 여부 Ca
velog.io