
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- decisiontree
- 클러스터링
- 공공빅데이터청년인턴
- data
- 2023공공빅데이터청년인재양성
- DL
- 데이터전처리
- Keras
- 머신러닝
- 데이터분석
- 오버샘플링
- datascience
- 빅데이터
- machinelearning
- 2023공공빅데이터청년인재양성후기
- 텍스트마이닝
- 2023공빅데
- ADsP3과목
- 공공빅데이터청년인재양성
- DeepLearning
- Kaggle
- NLP
- SQL
- k-means
- 공빅
- ML
- ADSP
- 공빅데
- 분석변수처리
- textmining
- Today
- Total
愛林
[Text Mining] 텍스트 마이닝 : 텍스트 전처리 - 토큰화(Tokenize) 본문
[Text Mining] 텍스트 마이닝 : 텍스트 전처리 - 토큰화(Tokenize)
愛林 2022. 7. 27. 20:46
텍스트마이닝 시작!
텍스트 마이닝 (Text Mining)
텍스트 마이닝이란, 텍스트(비정형데이터) 를 정형화된 데이터로 변환하는 기법이다.
이 과정에서 자연어 처리 기법을 사용한다.
문서를 일정한 길이 (sparse or dense) 의 벡터로 변환한다. (임베딩 하는 과정)
변환된 벡터에 통계적 패턴 분석, 머신 러닝(딥러닝) 기법을 적용한다.
관심이 있는 대상 혹은 사건에 대한 정보를 얻거나 결과를 예측할 수 있다.
우리는 텍스트 마이닝을
' 자연어 처리 기법을 통해 텍스트를 정형화된 데이터로 변환하고, 머신러닝 기법을 적용하여 우리가 관심이 있는
어떤 대상 및 사건에 대한 정보를 얻거나 예측하고자 하는 방법론 '
이라고 정의하고 갔다. (이해에 도움이 되기 위한 주관적 해석)
텍스트를 정형화시키는 방법으로는 문서에 나오는 단어를 정형화시키는 BOW, 카운트 벡터, TF-IDF 등이 있다.
하지만 이러한 방법은 정확한 이해에는 도움이 되지 않는다.
정확한 이해를 위해서는 단어의 순서가 중요하다. 그러므로, 우리는 문서를 단어의 시퀀스로 본다.
각 단어를 임베딩하고 문서를 임베딩 된 단어의 시퀀스로 표현한다.
이 분석을 위해서 우리는 주로 딥러닝 기법을 사용한다.
텍스트 마이닝 용어
- 문서 (Document) : 하나의 일관된 목적이나 주제를 갖고 쓰여진 글. 기사나 메일, 영화 리뷰 등
- 문장 (Sentence) : 생각이나 감정을 말로 표현할 때 완결된 내용을 나타내는 최소 단위.
문장들이 모이면 하나의 문서가 된다.
- 텍스트 (Text) : 분석의 대상이 되는 문자열로 상황에 따라 문서나, 문장이 될 수도 있다.
- 말뭉치(Corpus) : 언어 연구를 위해 컴퓨터가 텍스트를 가공, 처리, 분석할 수 있는 형태로 모아놓은 자료의 집합
텍스트 마이닝을 위해서 모아 놓은 유사한 문서들의 집합을 말한다.
텍스트 마이닝을 위해서는 토큰화(Tokenize), 정규화(Normalize), 품사 태깅(POS-tagging) 등의
자연어 전처리가 필요하다.
자연어 전처리를 위해 우리는 NLTK, KoNLPy 등을 사용할 것이다.
이외에도 통계학 지식, 시각화 기법, 머신러닝(Scikit-learn), 딥러닝(Keras, TensorFlow, PyTorch) 등을 사용한다.
텍스트 마이닝의 적용 분야
■ 언어 모형 (Language Model)
문서에서 주어진 앞 부분 단어들의 시퀀스를 이용하여 다음 단어의 예측을 수행하는 모형을 생성하는
프로세스이다. 문서에 나타낸 문맥을 학습하기 위해 가장 중요한 학습모형이다.
아무래도 언어에 대한 것을 잘 알수록 다음 단어에 대한 것을 잘 찾아내는 법일 것이기 때문에..
■ 문서 분류 (Text Classification)
주어진 문서에 대해 미리 정의된 클래스로 분류하는 작업이다.
감성분석, 스팸 메일 분류, 뉴스기사 분류 등 다양한 응용분야에 사용될 수 있다.
자연어 처리에서 가장 기본적이고, 활용범위가 넓은 분야 중 하나이다.
■ 문서 생성 (Text Generation)
사람이 쓴 것과 유사한 문장을 만들어내는 작업이다.
도전적이고 사람들의 관심을 끌기에 좋은 소재임에비해 아직 실질적인 응용분야는 많지 않다.
■ 문서 요약 (Summarization)
주어진 문서에서 중요하고 흥미 있는 내용을 추출하여 요약문을 생성하는 작업으로
Sequence - to - Sequence 의 전형적인 예이다.
■ 질의 응답 (Question Answering)
주어진 문장을 읽고 주어진 문제에 대해서 올바른 답을 생성하는 작업으로, 공학적으로는 문서 요약과 유사하다.
현재 가장 큰 주목을 받고 있는 챗봇에서 사용될 수 있는 기법이다.
■ 기계 번역 (Machine Translation)
한 언어로 작성된 문서를 다른 언어로 번역하는 작업으로,
두 언어를 모두 알고 있는 사람에게도 쉽지 않은 작업이다.
■ 토픽 모델링 (Topic Modeling)
여러 문서에서 공통적으로 등장하는 토픽을 추출하기 위한 방법이다.
다수의 문서에 잠재된 내용을 파악하기 위해 사용한다.
자연어 처리 - 텍스트 전처리
데이터 마이닝이 작업에 가까웠다면, 텍스트 마이닝, 전처리는 도구에 가깝다.
자연어 처리(NLP) 란,
컴퓨터와 인간 언어 간의 상호 작용과 관련된 언어학으로,
컴퓨터 과학 및 인공 지능의 하위 분야로서 특히 대량의 자연어 데이터를 처리하고 분석할 수 있도록
컴퓨터를 프로그래밍 해주는 방법을 말한다.
자연어처리의 단계로는
자연어로 쓰여진 글을 전처리하는 준비 단계(텍스트 전처리),
전처리된 결과를 컴퓨터가 다룰 수 있는 형태로 변환하는 단계, 그리고 이를 통해 다양한 분석을 수행하는 단계이다.
텍스트 전처리의 목적은 컴퓨터가 이해할 수 있도록 문서를 문자가 아닌 의미적인 최소 단위의 리스트로 변경하는 것이다.
예를 들면, "계절이 지나가는 하늘에는 가을로 가득 차 있습니다" 라는 문장은
컴퓨터 입장에서는 의미없는 ['계', '절', '이' ,.... ] 같은 문자의 나열에 불과하다.
이것을 컴퓨터도 알아듣도록 ['계절이', '지나가는' , '하늘에는', '가을로', '가득', '차', ' 있습니다'] 와 같이
각 요소가 의미를 갖는 리스트로 변환해야한다.
이것이 바로 텍스트 전처리이다.
텍스트 전처리의 과정으로는
분석에 불필요한 노이즈를 제거하는 정제 단계,
주어진 텍스트를 원하는 단위 (Token 이라고 한다.) 로 나누는 토큰화,
같은 의미임에도 다른 형태로 쓰인 단얻르을 통일시켜 표준 단어로 만드는 정규화,
토큰화한 단어의 품사를 파악해 부착해 정확한 의미를 파악하는 품사 태깅이 있다.
자연어 처리 실습
텍스트 전처리를 위해서는 NLTK (Natural Language Toolkit) 설치가 필요하다.
NLTK 는 교육용으로 개발된 자연어 처리 및 문서 분석용 파이썬 패키지로,
WordNet 을 비롯해 자연어 처리를 지원하는 다양한 라이브러리와 말뭉치, 예제들을 제공한다.
NLTK :: Natural Language Toolkit
Natural Language Toolkit NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries
www.nltk.org
NLTK 기본설치 패키지 외에 실습을 위해서 추가로 설치해줄 것들이 있다.
import nltk
nltk.download('punkt')
nltk.download('webtext')
nltk.download('wordnet')
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('omw-1.4')
!pip install konlpy
문장 토큰화 (sent_tokenize())
토큰화는 주어진 텍스트를 문장으로 나누고 싶을 때 사용한다. (사실 문장 토큰화는 사용빈도 낮음.)
보통은 단어 토큰화를 진행한다.
그렇지만 분석 단위를 문장으로 해야할 필요가 있을 때, 먼저 문장으로 나누고,
각 문장에 대해 이후 분석을 수행한다.
NLTK 의 sent_tokenize() 를 사용한다.
from nltk.tokenize import sent_tokenize
파이썬은 뭐든 import 해주면 돼서 너무너무 좋다.

para = "Hello everyone. It's good to see you. Let's start our text mining class!"
print(sent_tokenize(para))
단어 토큰화 (word_tokenize())
일반적으로 토큰화는 단어 토큰화를 말한다. 텍스트를 단어 단위로 분리하는 작업을 말한다.
문장 토큰화 없이 문서 전체에 바로 단어 토큰화 사용이 가능하다.
from nltk.tokenize import word_tokenizeimport시켜주자
para = "Hello everyone. It's good to see you. Let's start our text mining class!"
print(word_tokenize(para))
정규표현식을 이용한 토큰화
정규표현식도 따로 게시물 써야 하는데 언제쓰지..
정규표현식을 이용해서도 토큰화가 가능하다.
정규표현식은 regex 혹은 regexp 라고 줄여서 표현되며, 문자열에 대해서 원하는 검색 패턴을 지정할 수 있다.
파이썬 라이브러리 re 를 통해 지원한다.
import rere.findall("정규표현식")
re.findall("[abd]", "How are you, boy?")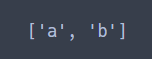
[abd] 는 문자열에서a, b, c 중 하나라도 일치하는 문자를 가져온다.
re.findall("[0123456789]", "3a7b5c9d")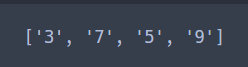
정규표현식을 Tokenize 할 때 사용해보자.
from nltk.tokenize import RegexpTokenizernltk 의 regexpTokenizer 를 사용한다.
text1 = "Sorry I can't go there"
tokenizer = RegexpTokenizer("[\w]{3,}") # 문자,숫자,언더바, 아포스트로피로 이루어진 3자 이상 단어
print(tokenizer.tokenize(text1.lower()))
[\w]{3,} 는 문자, 숫자, 언더바, 아포스트로피로 이루어진 3자 이상 단어를 찾는 정규표현식이다.
이 정규표현식으로 tokenizer 를 만들어준 후,
tokenizer.tokenize(text1.lower()) 로 text1 에 있는 문장을 토큰화 해준다.
토큰화 해주기 전에, text1 의 문장을 컴퓨터가 헷갈려하지 않도록 모두 소문자화 시켜주기 위해서
lower() 를 사용했다.
다음에는 텍스트 전처리의 나머지 과정들을 알아보자.
※ 해당 자료는 모두 공공 빅데이터 청년 인턴 교재들을 참고합니다.
'Data Science > Text Mining, 자연어처리' 카테고리의 다른 글
| [Text Mining] 텍스트 마이닝 - KoNLPy 를 이용한 한글 워드클라우드(Wordcloud) 만들기 (2) | 2022.07.30 |
|---|---|
| [Text Mining] 텍스트 마이닝 - 단어 빈도 분석, 그래프와 워드 클라우드 만들기 (2) | 2022.07.30 |
| [Text Mining] 텍스트 마이닝 - KoNLPy 를 사용한 한글 텍스트 전처리 (2) | 2022.07.30 |
| [Text Mining] 텍스트 마이닝 - 텍스트 전처리(Text Preprocessing) - 품사 태깅(POS-TAGGING) (2) | 2022.07.30 |
| [Text Mining] 텍스트 마이닝 : 텍스트 전처리 - 불용어 제거, 어간추출(Stemming), 표제어추출(Lemmatization) (3) | 2022.07.27 |



