
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 머신러닝
- Keras
- 2023공빅데
- 2023공공빅데이터청년인재양성후기
- 공빅데
- 공공빅데이터청년인재양성
- DeepLearning
- 공빅
- machinelearning
- k-means
- 오버샘플링
- Kaggle
- 데이터분석
- 데이터전처리
- ML
- ADSP
- 클러스터링
- ADsP3과목
- datascience
- NLP
- SQL
- 빅데이터
- 공공빅데이터청년인턴
- 분석변수처리
- 텍스트마이닝
- textmining
- 2023공공빅데이터청년인재양성
- data
- DL
- decisiontree
- Today
- Total
愛林
[Python/DL] 딥 러닝 (Deep Learning) (2) - 딥 러닝(Deep Learning) 의 학습 본문
[Python/DL] 딥 러닝 (Deep Learning) (2) - 딥 러닝(Deep Learning) 의 학습
愛林 2023. 1. 10. 14:11Deep Learning

이전 글 >
https://wndofla123.tistory.com/102
[Python/DL] 딥 러닝 (Deep Learning) (1) - 퍼셉트론(Perceptron)과 신경망
Deep Learning ANN 글을 적으면서 간결하게 공부했으나, 처음 보는 개념이라 헷갈리기도 했고 아직 능숙하게 사용하기에는 심층적인 공부가 더 필요할 것 같다는 생각이 들었다. 그래서 정리하는 글
wndofla123.tistory.com
이전에는 간결하게 퍼셉트론과 신경망, 그리고 활성화함수와 퍼셉트론을 행렬로서 살펴보았다.
이번엔 딥러닝에 학습에 필요한 손실 함수, Optimizer , Epoch , 역전파 등에 대해서 알아보자.
손실 함수 (Loss Function)
손실 함수는 말 그대로 실제값과 예측값의 차이를 수치화해주는 함수이다.
이 두 값의 차이인 오차가 클수록 손실 함수의 값은 크고 오차가 작을 수록 손실 함수의 값은 작아진다.
회귀에서는 평균 제곱 오차, 분류 문제에서는 Cross Entropy 를 주로 손실 함수로 사용한다.
손실 함수의 값을 최소화시키는 두 개의 매개변수인 가중치 w와 편향 b의 값을 찾는 것이 딥 러닝의 학습 방법이다.
손실 함수를 바탕으로 매개변수들의 값이 결정되기 때문에 어떤 손실 함수를 쓸 지에 대한 문제는 중요하다.
손실함수에 대해서 정리해보자.
1) MSE (Mean Spuad Error, MSE)
평균 제곱 오차. Mean Squad Error이다. 선형 회귀에서도 사용된다.
연속형 변수를 예측할 때 쓰인다.
model.compile(optimizer='adam', loss='mse', metrics=['mse'])compile() 함수 안의 파라미터인 loss에 'mse' 라고 쓰면 사용할 수 있다.
딥러닝으로 자연어 처리를 할 때에는 대부분 분류 문제를 수행하기 때문에 회귀에서 쓰이는 MSE보다는
아래의 Cross Entropy 함수들을 보통 사용한다.
2) 이진 크로스 엔트로피 (Binary Cross Entropy)
이항 교차 엔트로피라고도 부르는 손실 함수이다. 출력층에서 시그모이드 함수를 사용하는 이진 분류 (Binary Classification) 의 경우에는 binary_crossentropy 를 사용한다. 아래와 같이 사용할 수 있다.
로지스틱 회귀에서 사용했던 손실 함수와 같다.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])loss 에 binary_crossentropy 를 넣어 사용한다.
3) 범주형 크로스 엔트로피 (Categorical Cross Entropy)
범주형 교차 엔트로피라고 한다. 출력층에서 SoftMax 함수를 사용하는 다중 클래스 분류에서 사용된다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])위와 같이 loss 에 categorical crossentropy 를 써주면 된다.
만약, 레이블에 대해서 원-핫 인코딩 과정을 생략하고, 정수값을 가진 레이블에 대해서 다중 클래스 분류를
수행하고 싶다면 다음과 같이 'sparse_categorical_crossentropy' 를 사용한다.
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
이외에도 다양한 손실함수들을 tensorflow 에서 확인할 수 있다.
https://www.tensorflow.org/api_docs/python/tf/keras/losses
경사 하강법 (Gradient Descent)
손실 함수를 줄이면서 우리는 매개변수들의 값을 결정한다.
어떤 방식으로 손실함수를 줄이는 것일까?
이는 어떤 옵티마이저(Optimizer) 를 사용하느냐에 따라 다르다. 여기서 Batch(배치) 에 대해서 알아야 한다.
배치는 가중치 등의 매개변수 값을 조정하기 위해 사용하는 데이터의 양을 말한다.
배치 사이즈는 학습을 한 번 시킬 때 얼마만큼의 양을 학습시킬지이다.
경사 하강법이란, 가중치에 대한 손실함수의 최소값의 위치를 찾기 위해서 손실 함수를 미분하고,
그 미분값의 방향과 크기를 활용해서 가중치를 보상하는 방법이다.
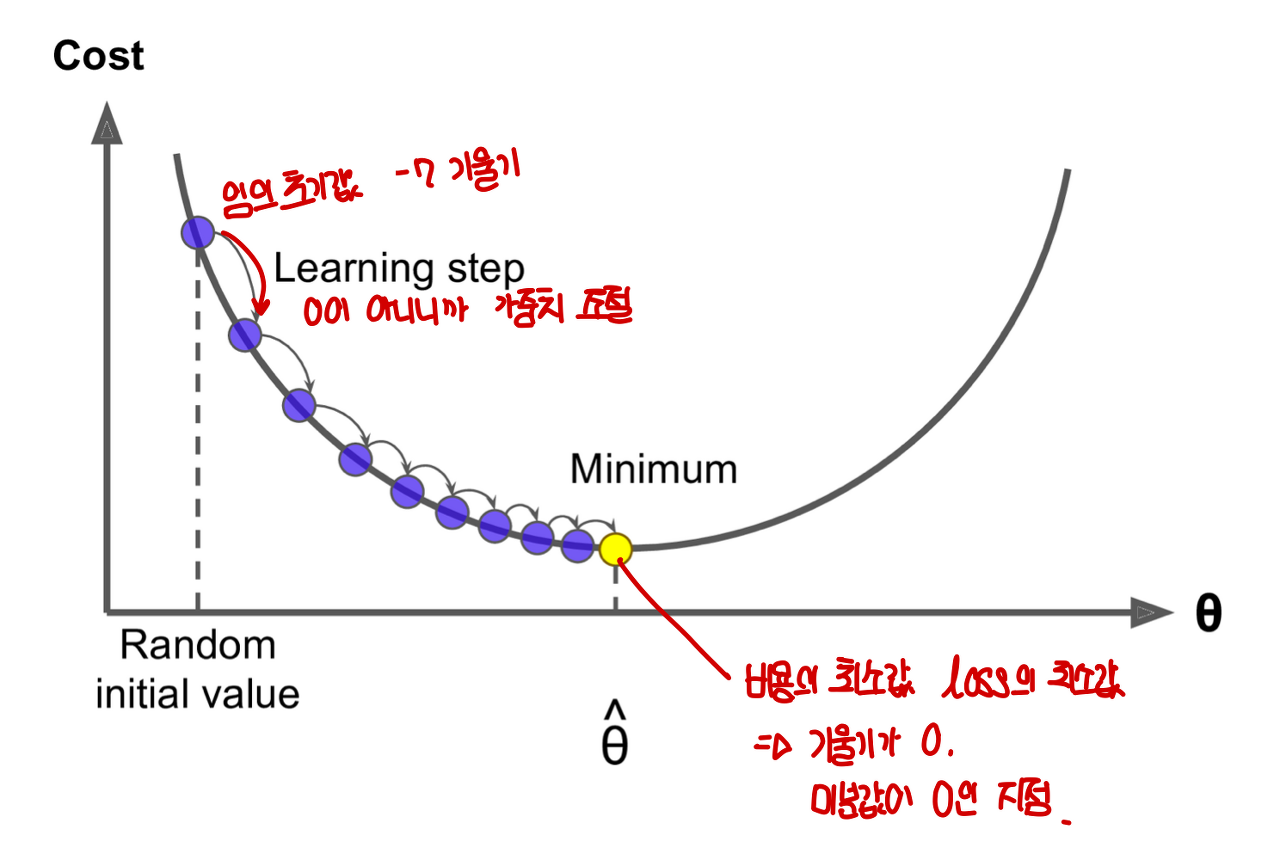
1) 배치 경사 하강법 (Batch Gradient Descent)
배치 경사 하강법은 가장 기본적인 경사 하강법이다. 배치 경사 하강법은 optimizer 중 하나로 오차를 구할 때 전체 데이터를 고려하는 경사 하강법이다. 딥러닝에서는 전체 데이터에 대한 한 번의 훈련수를 에포크(Epoch) 라고 한다.
배치 경사 하강법은 한 번의 에포크에 모든 매개변수 업데이트를 단 한 번 수행한다. 배치 경사 하강법은 전체 데이터를 고려해서 학습하므로 한 번의 매개 변수 업데이트에 시간이 오래 걸리고, 메모리를 크게 요구한다.
model.fit(X_train, y_train, batch_size=len(X_train))
2) 배치 크기가 1인 확률적 경사 하강법 (Stochastic Gradient Descent, SGD)
기존의 배치 경사 하강법은 전체 데이터에 대해서 계산을 하다보니 시간이 너무 오래걸린다는 단점이 있다.
배치 크기가 1인 확률적 경사하강법은 매개변수 값을 조정 시에 전체 데이터가 아니라 랜덤으로 선택한 하나의 데이터에 대해서만 계산하는 방법이다. 더 적은 데이터를 사용하기 때문에 더 빠르게 사용할 수 있다.

확률적 경사 하강법은 매개변수의 변경폭이 불안정하고, 때로는 배치 경사 하강법보다 정확도가 낮을 수도 있지만
하나의 데이터에 대해서만 메모리에 저장하면 되므로 자원이 적은 컴퓨터에서도 쉽게 사용이 가능하다는 장점이 있다.
model.fit(X_train, y_train, batch_size=1)
3) 미니 배치 경사 하강법 (Mini-Batch Gradient Descent)
전체 데이터도, 1개의 데이터도 아닐 때, 배치 크기를 지정하고 해당 데이터 개수만큼에 대해 계산하여 매개 변수의 값을 조정한다. 미니 배치 경사 하강법은 전체 데이터를 계산하는 것보다 빠르고, SGD보다는 안정적이다는 장점이 있다.
가장 많이 사용되는 경사 하강법이다.
model.fit(X_train, y_train, batch_size=128)위는 배치 사이즈를 128로 하여 미니 배치 경사 하강법을 진행했을 때를 보여준다.
배치 크기는 보통 2의 n제곱에 해당하는 숫자로 선정하는 것이 보편적이나, model.fit() 에서 배치 크기를 별도로
지정해주지 않을 경우에는 2의 5제곱에 해당하는 32로 설정된다.
옵티마이저 (Optimizer)
위에서 말한 경사하강법을 진행하기 위해서 다양한 옵티마이저를 사용한다.
경사하강법은 손실함수를 최적화시키는 방법이고, 옵티마이저는 경사하강법을 최적화 시키는 방법이므로,
이 옵티마이저가 손실함수를 최적화시키는 알고리즘이라고 이해할 수 있다.
옵티마이저 또한 여러가지 알고리즘이 존재한다.
여기서 옵티마이저들을 알아갈 때, 학습률(Learning Rate) 라는 개념이 등장한다.
학습률이란 경사 하강법을 진행할 때, 얼만큼 이동을 할 건지에 대한 거리의 비율을 학습률이라고 한다.

1) 모멘텀 (Momentum)
모멘텀은 관성이라는 물리학의 법칙을 응용하는 방법이다. 경사 하강법에 관성을 더해준다.
모멘텀은 경사 하강법에서 계산된 접선의 기울기에 한 시점 전의 접선기의 기울기값을 일정한 비율만큼 반영한다.
이렇게 하면 마치 언덕에서 공이 내려올 때, 중간에 작은 웅덩이에 빠지더라도 관성의 힘으로 넘어서는 효과를 준다.

전체 함수에 걸쳐 최소값을 글로벌 미니멈, 특정 구역에서의 최소값을 로컬 미니멈이라고 한다.
로컬 미니멈에 도달했을 때, 글로벌 미니멈이라고 잘못 인식하여 탈출하지 못하였을 상황에서 관성의 힘을 빌리면서
값이 조절되면 로컬 미니멈에서 탈출하고 글로벌 미니멈 내지는 더 낮은 로컬 미니멈으로 갈 수 있는 효과를 낸다.
tf.keras.optimizers.SGD(lr=0.01, momentum=0.9)위와 같이 사용된다.

2) 아다그라드 (Adagrad)
매개 변수들은 각자 의미하는 바가 다른데, 모든 매개변수에서 동일한 학습률(Learning rate) 를 적용하는 것은
비효율적이다. 아다그라드는 각 매개변수에 서로 다른 학습률을 적용시킨다.
이 때 변화가 많은 매개변수는 학습률이 작게 설정되고 변화가 적은 매개변수는 학습률을 높게 설정시킨다.
tf.keras.optimizers.Adagrad(lr=0.01, epsilon=1e-6)
3) 알엠에스프롭 (RMSprop)
아다그라드는 학습을 계속 진행한 경우, 나중에 가서는 학습률이 지나치게 떨어진다는 단점이 있다.
이를 다른 수식으로 대체하여 이러한 단점을 개선했다.
tf.keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-06)
4) 아담 (Adam)
아담은 RMSprop과 Momentum 2가지를 합친 방법으로, 방향과 학습률 두 가지를 모두 잡기 위해 고안된 방법이다.
보통 가장 많이 사용되는 옵티마이저이다.
진행하던 속도에 관성을 주고, 최근 경로의 곡면의 변화량에 따른 적응적 학습률을 가졌다.
매우 넓은 범위의 아키텍쳐를 가진 서로 다른 신경망에서 잘 작동한다는 것으 증명되어서,
일반적 알고리즘에 현재 가장 많이 사용되고 있다.
어떤 Optimizer 를 사용할 지 모르겠다면 그냥 Adam 을 써라 라는 말도 있다.

보통 Adam 의 Hyper-Parameter 는 다음이 추천된다.

보통 베타1, 베타2, ϵ 값은 고정시키고, 에타를 여러 값으로 시도해가면서 가장 잘 작동되는
최적의 값을 찾는다.
이외에도 여러가지 옵티마이저 알고리즘들이 존재한다.
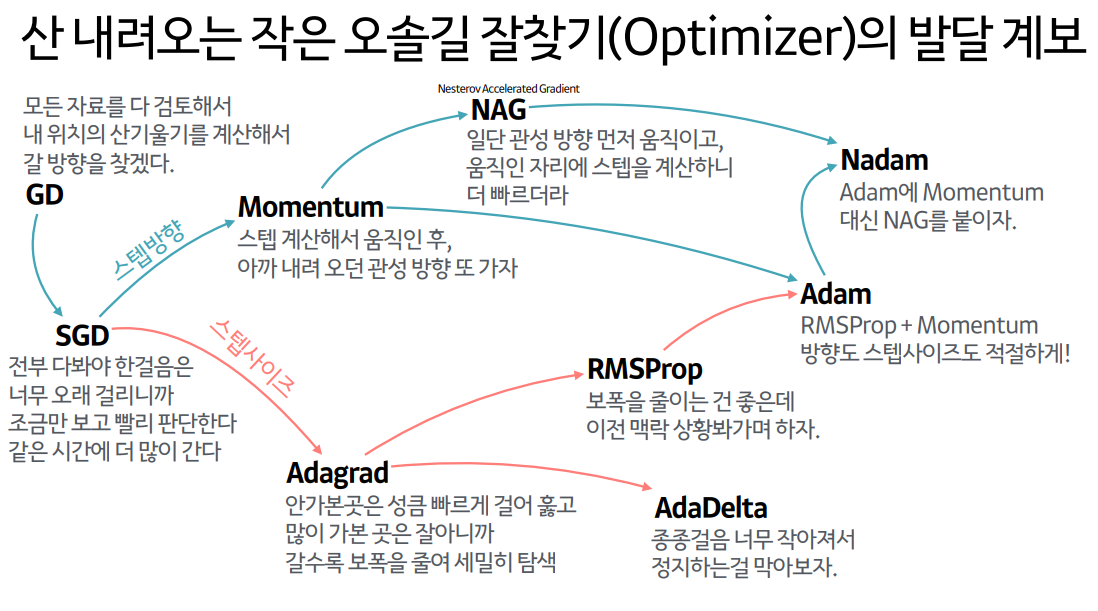
각 Optimizer 들은 compile의 optimizer 에서 호출된다.
예를 들어 Adam 은 다음과 같이 코드를 작성한다.
adam = tf.keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['acc'])
그러나 따로 adam을 정의해주지 않고 optimizer = 'adam' 으로 작성하더라도 문제가 없다.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])이외에도 ' adam' 대신에 'sgd', 'rmsprop' 과 같이 옵티마이저 이름을 넣어줄 수 있다.
Epochs and Batchsize Iteration
모델은 실제값과 예측값의 오차로부터 Optimizer 를 통해 가중치를 업데이트하여 최적화시킨다.
이것이 딥러닝의 학습 방법이다.
이를 현실에 학습에 비유하면 사람이 문제지의 문제를 풀고, 정답지의 정답을 보면서 채점을 하며 부족한 것을
고치면서 머릿속의 지식을 업데이트 하는 과정이다.
우리는 몇 문제를 풀고 매길 지를 선택할 수 있다. 또한 문제지를 몇 번 공부할 지도 선택할 수 있다.
딥러닝 모델도 이와 같은 방식으로 모델을 만들 수 있는데, 에포크, 배치 사이즈, 이터레이션으로 이를 설정한다.

같은 문제지를 몇 번 반복하여 풀 지를 결정하는 것은 에포크(Epoch) 이다.
에포크가 적절하지 못하면, 모델이 과적합되거나 과소적합 될 수 있다.
전체 문제지에서 몇 개씩을 풀고 채점할 지를 결정하는 것은 배치 크기 (Batch Size) 이다.
사람이 문제를 풀고 정답을 보면서 부족했던 점을 인식하고, 지식이 업데이트 되는 것이 기계 입장에서는
실제값과 예측값으로부터 오차를 계산하고 옵티마이저가 매개변수를 업데이트하는 것인데,
여기서 업데이트가 시작되는 시점이 실제값을 확인하는 시점이다.
사람이 2000 문제가 수록되어 있는 문제지의 문제를 200개 단위로 풀고 채점할 시 배치 크기는 200이 된다.
기계의 배치 크기가 200이면 기계는 2000개를 10번 나누어 200개씩 풀고 가중치를 업데이트 한다.
여기서 2000개를 10번 나누어 200개씩 푼다고 할 때 배치의 수(Iteration)는 10이다.
배치의 크기(Batch size)는 200이다.
배치 크기와 배치의 수는 서로 다른 개념이므로 주의하자.
배치의 수는 이터레이션이라고 한다. 배치의 크기는 배치 사이즈라고 한다.
이터레이션(Iteration) 은 스텝(Step) 이라고 부르기도 한다.
과적합 (Overfitting)
과적합이란 모델이 학습데이터를 과하게 학습시켜 훈련 데이터에 있는 노이즈까지 학습해
학습 데이터에서는 정확도가 높음에도 불구하고 테스트 데이터에서는 성능이 제대로 나오지 않는 것을 의미한다.
이러한 과적합을 막아야 좋은 모델이 만들어진다.
딥러닝에서 과적합을 막는 방법은 여러가지가 있다.
1) 데이터 양을 늘리기
모델은 데이터의 양이 적은 경우 해당 데이터의 패턴이나 노이즈까지 학습될 가능성이 크다.
그러므로 과적합 현상이 발생될 확률이 늘어나게 된다.
이 때 데이터의 양을 증식(Data Augmentation) 시킨다. 이미지 데이터의 경우 데이터 증식이 많이 사용되는데,
이미지를 돌리거나 노이즈를 추가하거나 일부분을 수정하는 식으로 데이터를 증식시킨다.
텍스트 데이터의 경우 이미 번역한 데이터를 재번역하여 새로운 데이터를 만들어내는 역변역 등이 있다.
2) 모델의 복잡도 줄이기 : 가중치 규제 (Regularation)
모델의 복잡도는 은닉층(Hidden Layer)이 많이 결정한다.
과적합을 줄이기 위해서는 이러한 은닉층을 줄이거나, 매개변수의 수를 줄이는 방법이 있다.
매개변수의 수를 수용력(Capacity) 라고도 한다.
복잡도를 줄이는 방법으로는 가중치 규제 (Regularizatioin) 이 있다.
- L1 규제 : 가중치 w들의 절대값 합계를 비용 함수에 추가한다. L1 노름이라고도 한다.
- L2 규제 : 모든 가중치 w들의 제곱합을 비용 함수에 추가한다. L2 노름이라고도 한다.
두 식 모두 비용 함수를 최소화시키기 위해서는 가중치의 값을 작아지게 만들어야 한다.
L1 규제를 살펴보면, 비용함수의 절대값이 식에 사용되므로 비용함수를 줄이기 위해서는 양 뿐만 아니라
음을 갖고 있더라도 값이 커서는 안되므로 가중치가 0이 되거나 0에 가깝도록 만들어야 한다.
여기서 가중치가 0에 가깝게 된다는 것은 그 가중치를 가진 특성은 모델에서 비중이 작아진다는 것을 의미한다.
L2 규제 또한 제곱합이기에 위와 비슷하지만 L1과 다르게 완전히 가중치를 0으로 만든다기 보다는 0에 가깝도록
만들기 때문에 L2 규제가 더 많이 사용된다. L2 는 가중치 감쇠(Weight Decay) 라고도 불린다.
규제는 정규화라고도 부르지만 이는 Normalization 과 혼동될 수 있으므로 참고한 책에서는 규제라고 번역했다.
이게 더 맞는표현같다.
3) 드롭 아웃 (DropOut)
드롭아웃은 학습 과정에서 신경망의 일부를 사용하지 않는 방법이다.

드롭아웃의 비율이 0.5로 설정되었을 때, 이는 학습과정에서 랜덤으로 절반의 뉴런을 사용하지 않고,
절반의 뉴런만을 사용한다는 것이 된다.
드롭아웃은 신경망 학습 시에만 사용하고 예측시에는 사용하지 않는 것이 일반적이나,
학습 시에 인공 신경망이 특정뉴런 또는 특정 조합에 너무 의존적이게 되는 것을 방지해주고,
매번 랜덤 선택으로 뉴런들을 사용하지 않으므로 서로 다른 신경망들을 앙상블시켜 사용하는 것 같은 효과를 내어 과적합을 방지한다.
keras 에서는 다음과 같은 방법으로 Drop Out 을 모델에 추가시킬 수 있다.
layers 에서 Dropout 을 import 시켜야한다.
layer 사이에 끼워넣어주면 된다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Dense
max_words = 10000
num_classes = 46
model = Sequential()
model.add(Dense(256, input_shape=(max_words,), activation='relu'))
model.add(Dropout(0.5)) # 드롭아웃 추가. 비율은 50%
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5)) # 드롭아웃 추가. 비율은 50%
model.add(Dense(num_classes, activation='softmax'))
참고
07-04 딥 러닝의 학습 방법
딥 러닝의 학습 방법의 이해를 위해 필요한 개념인 손실 함수, 옵티마이저, 에포크의 개념에 대해서 정리합니다. ## 1. 손실 함수(Loss function) 
딥러닝에 이용되는 Optimizer 는 대부분 Adam 을 쓰고 있다. ..딥러닝 은 입력층과 출력층 사이에 여러 개의 은닉층으로 이루어진 신경망이다.층이 깊어질수록 모듈과 함수에 따른 하이퍼파라미터...
velog.io



