
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 빅데이터
- ADsP3과목
- DL
- 머신러닝
- NLP
- ADSP
- Keras
- 데이터전처리
- 분석변수처리
- 2023공공빅데이터청년인재양성
- k-means
- 공공빅데이터청년인재양성
- machinelearning
- 텍스트마이닝
- ML
- datascience
- textmining
- DeepLearning
- Kaggle
- 2023공빅데
- 공빅데
- 오버샘플링
- decisiontree
- 클러스터링
- data
- 공빅
- SQL
- 2023공공빅데이터청년인재양성후기
- 공공빅데이터청년인턴
- 데이터분석
- Today
- Total
愛林
[Data/Data Analysis] Kaggle : 주택 가격 예측 모델 만들기 (House Prices: Advanced Regression Techniques) - (2) 본문
[Data/Data Analysis] Kaggle : 주택 가격 예측 모델 만들기 (House Prices: Advanced Regression Techniques) - (2)
愛林 2022. 11. 22. 10:41House Prices Data Analysis

www.kaggle.com/c/house-prices-advanced-regression-techniques
House Prices - Advanced Regression Techniques | Kaggle
www.kaggle.com
이전 글 보기
https://wndofla123.tistory.com/83
[Data/Data Analysis] Kaggle - 주택 가격 예측 모델 만들기 (House Prices: Advanced Regression Techniques) - (1)
House Prices Data Analysis www.kaggle.com/c/house-prices-advanced-regression-techniques House Prices - Advanced Regression Techniques | Kaggle www.kaggle.com 너무나도 유명한 House Prices Data 를 분..
wndofla123.tistory.com
이전 글에서 주택 데이터의 EDA, 전처리를 했다.
변수가 많아서 포스팅이 길어져 (2) 까지 오게 된 ..
이번 게시글에서는 이제 주택 가격을 예측하는 모델을 만들어보자.
모델링
먼저 모델링에 필요한 패키지들을 import 해준다.
from sklearn.model_selection import KFold, cross_val_score, GridSearchCV
from sklearn.metrics import mean_squared_error
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.linear_model import ElasticNet, Lasso, LinearRegression
1. 단순선형회귀
from sklearn.preprocessing import RobustScalerrbst_scaler=RobustScaler()
X_rbst=rbst_scaler.fit_transform(new_train)
test_rbst=rbst_scaler.transform(new_test)중앙값과 IQR까지 이용하여 이상값의 영향을 최소화하도록 한다.
import statsmodels.api as smmodel = sm.OLS(target.values, new_train)re = model.fit()re.summary()


칼럼이 너무 많으니 하나하나 다 적지는 않겠다 ..
변수 중에 P-value 가 높은 값들이 있어 다중공선성이 의심이 된다.
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif['Features'] = new_train.columns
vif['vif'] = [variance_inflation_factor(
new_train.values, i) for i in range(new_train.shape[1])]다중공선성을 확인하기 위해 분산팽창요인, VIF 를 사용했다.
vif.sort_values(by='vif',ascending=False)[165:1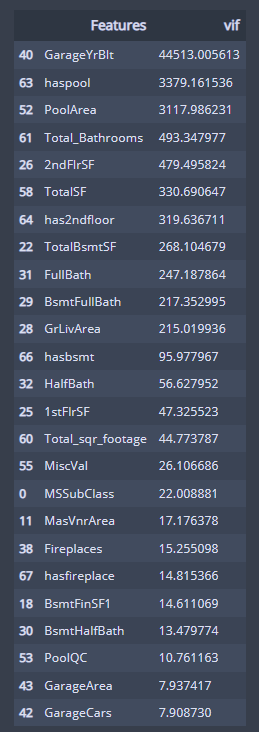
VIF는 독립변수가 여러 개 있을 때, 특정 독립변수를 종속변수로 하고 나머지 독립변수를
독립변수로 하여서 회귀분석을 수행하는 것이다.
이를 통해 변수 간의 관계성을 측정할 수 있다.
여기서, VIF가 10을 넘으면 다중공선성이 존재하는 것으로 간주하는데,
여기서는 VIF가 10을 넘는 것들이 많이 보인다.
다중공선성이 있다는 것.
이런 다중공선성을 처리하기 위해서는
- 다중공선성에 Robust 한 트리모델을 사용하는 방법
- 변수 제거 및 FE, 변환 등을 통해서 대체하는 방법
- 관측값을 늘려서 표본의 크기를 증가시키는 방법
이 있다.
우리는 RobustScaler 를 사용해서 Robust시키는 방법을 수행해보자.
from sklearn.preprocessing import RobustScaler
rbst_scaler=RobustScaler()
X_rbst=rbst_scaler.fit_transform(new_train)
test_rbst=rbst_scaler.transform(new_test)데이터를 넣어주고 RobustScaler 를 사용하여 스케일링해주었다.
2. K-Fold
k-fold 를 이용하여 데이터를 K개로 돌아가며 학습, 검증하는 방식을 사용하여
학습에 쓸 모델을 선정한다.
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFoldkfold = KFold(n_splits=4)random_state = 1
reg = []
reg.append(Lasso(random_state = random_state))
reg.append(ElasticNet(random_state = random_state))
reg.append(RandomForestRegressor(random_state=random_state))
reg.append(GradientBoostingRegressor(random_state=random_state))
reg.append(XGBRegressor(silent=True,random_state=random_state))
reg.append(LGBMRegressor(verbose_eval=False,random_state = random_state))라쏘회귀 , 엘라스틱넷, 랜덤포레스트, 그라디언트부스트 ,XGB, LGBM 을 학습시켰다.
reg_results = []
for regre in reg :
reg_results.append(np.mean(np.sqrt(-cross_val_score(regre, X_rbst, y = target,scoring = 'neg_mean_squared_error',
cv = kfold, n_jobs=-4))))reg_means = []
reg_std = []
for reg_result in reg_results:
reg_means.append(reg_result.mean())
reg_std.append(reg_result.std())reg_re = pd.DataFrame({"CrossValMeans":reg_means,"CrossValerrors": reg_std})
reg_re
CrossValMeans 를 보았을 때, 3,4,5 가 값이 괜찮게 나왔으므로 이에 해당하는
Gradient Boosting, XGBoost, LGBM 모델을 사용할 것이다.
3. 파라미터 튜닝
최적의 파라미터를 찾아주는 GridSearchCV를 사용해서
최적의 파라미터를 찾아서 튜닝해주었다.
# Gradient boosting 파라미터 튜닝
GBC = GradientBoostingRegressor()
gb_param_grid = {'n_estimators' : [100,200,300],
'learning_rate': [0.1, 0.05, 0.01],
'max_depth': [4, 8],
'min_samples_leaf': [100,150],
'max_features': [0.3, 0.1]
}
gsGBC = GridSearchCV(GBC,param_grid = gb_param_grid, cv=kfold, scoring="neg_mean_squared_error", n_jobs= 4, verbose = 1)
gsGBC.fit(X_rbst,target)
GBC_best = gsGBC.best_estimator_
# 최고 점수
gsGBC.best_score_Fitting 4 folds for each of 72 candidates, totalling 288 fits
-0.017296662436834066
# XGBoost 파라미터 튜닝
XGB = XGBRegressor()
xgb_param_grid = {'learning_rate': [1,0.1,0.01,0.001],
'n_estimators': [50, 100, 200, 500, 1000],
'max_depth' : [1,3,5,10,50]}
gsXGB = GridSearchCV(XGB,param_grid = xgb_param_grid, cv=kfold, scoring="neg_mean_squared_error", n_jobs= 4, verbose = 1)
gsXGB.fit(X_rbst,target)
XGB_best = gsXGB.best_estimator_
# 최고 점수
gsXGB.best_score_Fitting 4 folds for each of 72 candidates, totalling 288 fits
-0.017296662436834066
#LGBM Regressor 파라미터 튜닝
LGB = LGBMRegressor()
lgb_param_grid = {
'num_leaves' : [1,5,10],
'learning_rate': [1,0.1,0.01,0.001],
'n_estimators': [50, 100, 200, 500, 1000,5000],
'max_depth': [15,20,25],
'num_leaves': [50, 100, 200],
'min_split_gain': [0.3, 0.4],
}
gsLGB = GridSearchCV(LGB,param_grid = lgb_param_grid, cv=kfold, scoring="neg_mean_squared_error", n_jobs= 4, verbose = 1)
gsLGB.fit(X_rbst,target)
LGB_best = gsLGB.best_estimator_
# 최고 점수
gsLGB.best_score_Fitting 4 folds for each of 432 candidates, totalling 1728 fits
-0.018548377122561577
4. 앙상블
test_Survived_GBC = pd.Series(GBC_best.predict(test_rbst), name="GBC")
test_Survived_XGB = pd.Series(XGB_best.predict(test_rbst), name="XGB")
test_Survived_LGB = pd.Series(LGB_best.predict(test_rbst), name="LGB")
ensemble_results = pd.concat([test_Survived_XGB,test_Survived_LGB,
test_Survived_GBC],axis=1)
g= sns.heatmap(ensemble_results.corr(),annot=True)3가지 모델을 히트맵을 통해 상관관계를 비교해보고,
상관성이 높은 XGB와 GBC 모델을 이용하여 앙상블 모델을 만든다.
도움받은 분들
말이 도움이지 그대로 따라한 것이나 다름이 없음.
저는 이 분들의 것을 합쳐서 필사하며 공부했습니다 !
[Kaggle] 보스턴 주택 가격 예측(House Prices: Advanced Regression Techniques)
Intro캐글의 고전적인 문제이며 머신러닝을 공부하는 사람이라면 누구나 한번쯤 다뤄봤을 Boston house price Dataset을 통해 regression하는 과정을 소개하려 한다. 정식 competition 명칭은 'House Prices: Advanced
velog.io
https://minding-deep-learning.tistory.com/16
[Kaggle] House Prices Prediction : 보스턴 주택가격 예측 - 1. EDA & Feature Engineering
[파이썬 라이브러리를 활용한 머신러닝] 책을 공부하던 때 처음 접해보았던 머신러닝 회귀 문제의 대표문제, Kaggle의 House Prices 예측 데이터셋을 다시 한번 살펴보는 시간을 가졌다. 데이터셋은 K
minding-deep-learning.tistory.com
https://minding-deep-learning.tistory.com/17?category=976247
[Kaggle] House Prices Prediction : 보스턴 주택가격 예측 - 2. Modeling & Prediction
[파이썬 라이브러리를 활용한 머신러닝] 책을 공부하던 때 처음 접해보았던 머신러닝 회귀 문제의 대표문제, Kaggle의 House Prices 예측 데이터셋을 다시 한번 살펴보는 시간을 가졌다. 데이터셋은 K
minding-deep-learning.tistory.com
https://hong-yp-ml-records.tistory.com/2
[House Prices] Tutorial For Korean Beginners - 캐글 집값 예측 part 1
House Prices Predict 아이오와 주 에임스에 있는 주거용 주택의 모든 측면을 설명하는 79 개의 변수로 주택의 판매가격을 예측하는 Competition입니다. Introduction 본 커널은 다수의 고수분들이 올려주신
hong-yp-ml-records.tistory.com
https://www.kaggle.com/code/munmun2004/house-prices-for-begginers/notebook
[한글커널][House Prices]보스턴 집값 예측 for Begginers
Explore and run machine learning code with Kaggle Notebooks | Using data from House Prices - Advanced Regression Techniques
www.kaggle.com
www.kaggle.com/munmun2004/house-prices-for-begginers
[한글커널][House Prices]보스턴 집값 예측 for Begginers
Explore and run machine learning code with Kaggle Notebooks | Using data from House Prices - Advanced Regression Techniques
www.kaggle.com



