
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ADsP3과목
- SQL
- data
- Keras
- 공빅데
- 데이터전처리
- 오버샘플링
- NLP
- 머신러닝
- 빅데이터
- 데이터분석
- textmining
- 공빅
- 2023공빅데
- ML
- 공공빅데이터청년인재양성
- DeepLearning
- Kaggle
- ADSP
- decisiontree
- 분석변수처리
- 공공빅데이터청년인턴
- k-means
- machinelearning
- 2023공공빅데이터청년인재양성후기
- 텍스트마이닝
- DL
- datascience
- 2023공공빅데이터청년인재양성
- 클러스터링
- Today
- Total
愛林
[Data/Data Analysis] Kaggle : Titanic 생존자 예측모델 만들기 본문
Titanic Data Analysis

https://www.kaggle.com/c/titanic/data
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
넘나도 유명한 Kaggle 의 타이타닉 데이터를 이용해서 생존자 예측모델을 만들어보자.
나는 당장 예측모델을 만들어볼 능력이 되지 않으니 !
다른 사람들을 따라해볼 것이다. ㅋ
이 Competition의 목적은

바로 어떤 승객이 살아남는가? 이다.
데이터에는 다양한 승객들의 정보가 담겨있다. (티켓 클래스, 성별, 이름 등)
데이터를 통해 살아남은 승객들의 경향성을 살펴보고,
어떤 정보를 가진 승객이 살아남는가에 대한 예측모델을 만드는 것이 목적이다.
데이터 살펴보기
분석에 들어가기 전, 먼저 Data Dictionary 를 살펴보고 어떤 데이터들이 있는 지 파악해보자.
Data Dictionary
- Survived : 0 = 사망, 1 = 생존
- Pclass : 1 = 1등석, 2 = 2등석, 3 = 3등석
- Sex : male = 남성, female = 여성
- Age : 나이
- SibSp : 타이타닉 호에 동승한 자매 / 배우자의 수
- Parch : 타이타닉 호에 동승한 부모 / 자식의 수
- Ticket : 티켓 번호
- Fare : 승객 요금
- Cabin : 방 호수
- Embarked : 탑승지, C = 셰르부르, Q = 퀸즈타운, S = 사우샘프턴
먼저 필요한 라이브러리들을 불러와주고, train, test 데이터를 불러왔다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
# 머신러닝
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
import warnings
warnings.filterwarnings(action='ignore')train = pd.read_csv('train.csv')
train.head()

test = pd.read_csv('test.csv')
test.head()
test 데이터에는 Survived 칼럼이 없는 것을 확인했다.
목적변수는 Survived.
나머지 변수들은 설명변수가 되겠다.
print(train.columns.values)['PassengerId' 'Survived' 'Pclass' 'Name' 'Sex' 'Age' 'SibSp' 'Parch'
'Ticket' 'Fare' 'Cabin' 'Embarked']
print('train data shape: ', train.shape)
print('test data shape: ', test.shape)
print()
print('----------[train infomation]----------')
print(train.info())
print()
print('----------[test infomation]----------')
print(test.info())train data shape: (891, 12)
test data shape: (418, 11)
----------[train infomation]----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
----------[test infomation]----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
NoneAge(나이), Cabin(객실번호), Embarked(탑승지) column 에 결측치들이 있는 것을 확인했다.
이후 처리가 필요할 것 같다.
EDA (탐색적 데이터 분석) 진행
파이차트 외 여러가지 시각화 방법을 통해서 탐색적 데이터 분석을 진행했다.
각각의 생존률을 보기에 파이차트가 적절할 것 같아 Sex, PClass, Embarked 는 파이차트를 활용했다.
# 파이차트 함수 생성
def pie_chart(feature):
feature_ratio = train[feature].value_counts(sort=False)
feature_size = feature_ratio.size
feature_index = feature_ratio.index
survived = train[train['Survived'] == 1][feature].value_counts()
dead = train[train['Survived'] == 0][feature].value_counts()
plt.plot(aspect='auto')
plt.pie(feature_ratio, labels=feature_index, autopct='%1.1f%%')
plt.title(feature + '\'s ratio in total')
plt.show()
for i, index in enumerate(feature_index):
plt.subplot(1, feature_size + 1, i + 1, aspect='equal')
plt.pie([survived[index], dead[index]], labels=['Survivied', 'Dead'], autopct='%1.1f%%')
plt.title(str(index) + '\'s ratio')
plt.show()
1. 성별 Sex
pie_chart('Sex') # 성별 파이차트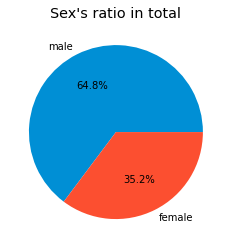
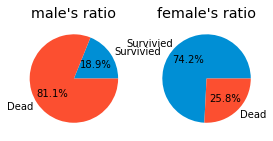
총 남성의 수는 남자가 약 65% 정도로 더 많았으나, 생존 확률은 여성이 훨씬 높았다.
여성의 수가 작다는 점을 배제할 수 있을 지는 잘 모르겠다.
2. 좌석등급 PClass
# Class 좌석등급별
pie_chart('Pclass')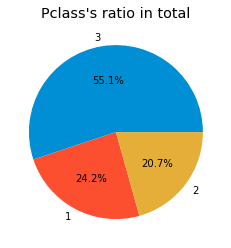
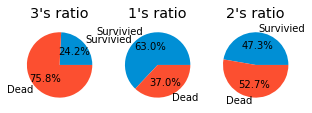
총 Class는 3등급의 인원수가 훨씬 많았으나, 생존률은 1등급이 더 많이 생존한 것을 확인할 수 있다.
1>2>3 Class 순으로 생존률이 높은 것을 확인했다.
아무래도 돈 많은 사람이 더 많이 생존한 것 같다.
3. 승선한 장소 Embarked
# 승선한 장소
pie_chart('Embarked')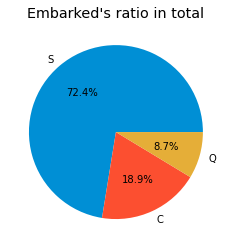
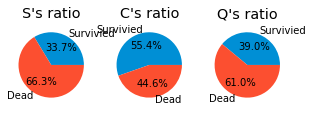
S > C > Q 순으로 승선한 장소의 인원수가 많았으나,
생존은 C > Q >S 순으로 생존확률이 높았다. S 가 사람이 많아서 죽은 사람도 많다는 가능성을
배제할 수는 없을 것 같다.
크게 생존과 관련이 있는 변수인 지는 알 수 없다. 다른 변수와의 관계를 살펴볼 필요가 있다. (나이나, 탑승등급)
위와 비교했을 때, Q나 C가 좀 더 잘 사는 사람들이 탑승을 많이 한 장소라고 유추할 수 있을 것 같다.
4. 동반한 형제자매 SibSp
이후로는 가짓수가 많아서 파이차트를 이용하면 어지러워질 것 같아 Bar plot 을 이용했다.
그래도 파이차트로 한 번 확인해보았을 때,
# 동반한 형제자매 생존
pie_chart('SibSp')
전체적으로는 형제자매가 없는 (=0)인 사람들이 많았다.
# 동반한 형제자매 생존
sbs=train[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)
print(sbs)
sbs.plot("SibSp",kind="bar").set_xlabel("SibSp") SibSp Survived
1 1 0.535885
2 2 0.464286
0 0 0.345395
3 3 0.250000
4 4 0.166667
5 5 0.000000
6 8 0.000000
Text(0.5, 0, 'SibSp')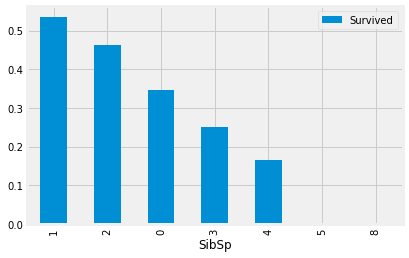
1 > 2 > 0 > 3 > 4 순으로 생존했다.
형제자매가 적을수록 더 생존률이 높은 것을 알 수 있었다.
5. 동반한 부모자녀 Parch
# 동반한 부모자녀 생존
pie_chart('Parch')
동반한 부모자녀가 0명인 승객들이 많았다.
# 동반한 부모자녀 생존
pcs=train[["Parch", "Survived"]].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)
print(pcs)
pcs.plot("Parch",kind="bar").set_xlabel("Parch") Parch Survived
3 3 0.600000
1 1 0.550847
2 2 0.500000
0 0 0.343658
5 5 0.200000
4 4 0.000000
6 6 0.000000
Text(0.5, 0, 'Parch')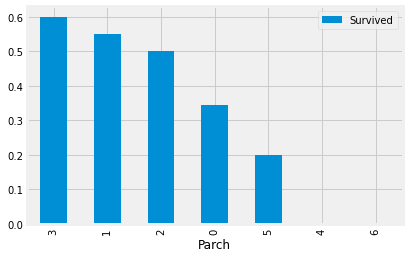
의외로 동반한 부모자녀가 3명인 사람들이 가장 많이 생존했고, 다음은 1, 2, 0 순이었다.
하지만 이는 비율이기 때문에, 사람들의 수를 고려하면 3명인 사람이 그만큼 적었기에 비율이
높게 나왔을 확률이 높다는 생각이 든다.
6. 생존자의 나이 Age
# 생존자 나이
g = sns.FacetGrid(train, col='Survived')
g.map(plt.hist, 'Age', bins=20)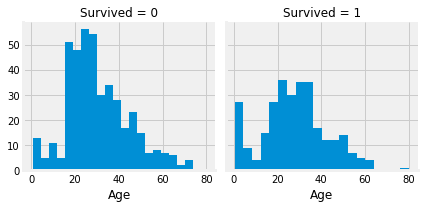
연속적인 데이터이므로 히스토그램을 그려 확인했을 때, 2-30대에서 사망자가 가장 많이 나왔다.
그리고 생존률은 0-10대가 의외로 높게 나오고, 사망률은 매우 낮았다.
0-10대에서 50대 이후 고령층으로 넘어갈수록 사망률이 줄었다. 그러나 둘 다 크게 차이가 없어보인다.
나이와 크게 연관이 없는 걸까?
생존구분이 비교적 명확한 변수와의 결합을 통해 설명력 보유 여부를 살펴보자.
다중변수 비교 1. 나이(Age) & 객실등급(PClass)
grid = sns.FacetGrid(train, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();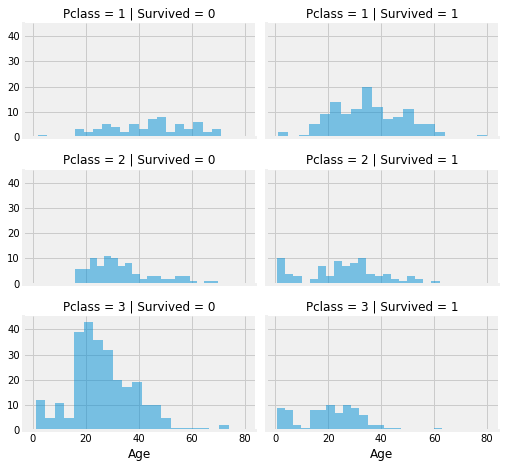
Class 1의 경우, 나이가 어리던 말던 살아남은 비율이 높고 대칭적인 것을 확인할 수 있다.
Class 2의 경우, 생존자와 사망자가 비율이 비슷하지만 어린 층의 비율이 높은 것을 확인할 수 있다.
Class 3의 경우, 사망자의 수가 훨씬 많지만, 어린층이 대부분 살아남았음을 알 수 있다.
그러므로, 나이와 생존의 관계성은 확실해보인다.
다중변수 비교 2. 성별(Sex) & 객실등급(PClass)
여자일수록, 객실등급이 높을 수록 생존자가 많은 것은 위의 변수들만 봐도 알 수 있지만,
한 번 더 확인해보자.
pd.crosstab([train.Sex,train.Survived],train.Pclass,margins=True).style.background_gradient(cmap='summer_r')
여자일수록 생존자가 더 많고, 1등급일수록 생존률이 높았다.
1등급 남자 생존자보다 3등급 남자 생존자가 더 많은데, 비율로 따져보자면 3등급 남성 사망자는 300명이다. (...)
비율로 따져보았을 때 등급이 낮고 남성일수록 생존률이 낮은 것을 알 수 있다.
sns.factorplot('Pclass','Survived',hue='Sex',data=train)
이렇게 비율로 따져보았을 때, 확실히 여성일수록, 1등급일수록 생존률이 높다는 것을 알 수 있다.
이 두 변수는 생존과 관련이 있다.
# 바이올린 플롯으로 객실과 나이에 대한 생존자 비율, 성별과 나이에 대한 생존자 비율을 살펴본다.
f,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot("Pclass","Age",hue="Survived",data=train,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age VS Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age",hue="Survived",data=train,split=True,ax=ax[1])
ax[1].set_title('Sex and Age VS Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()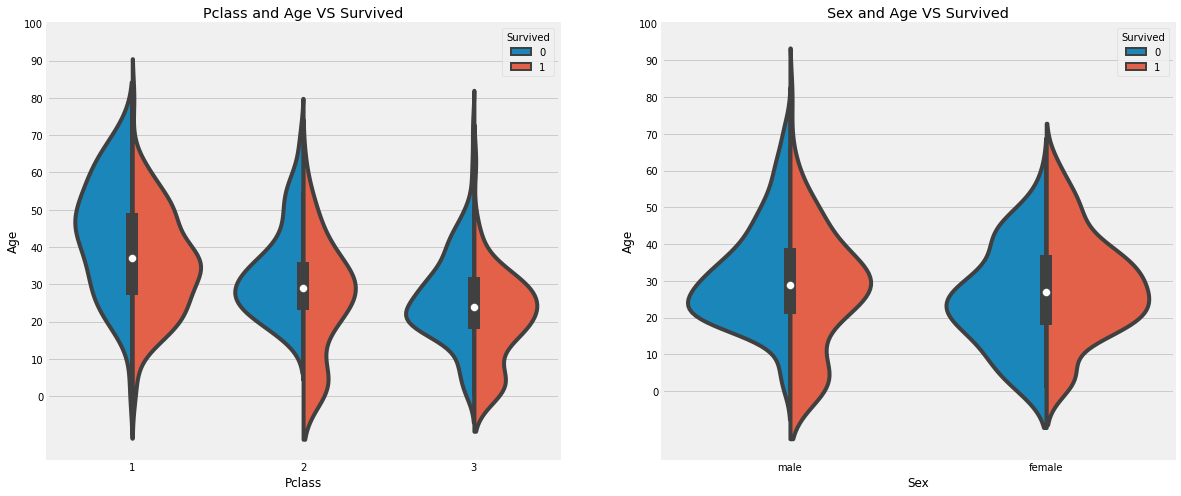
다중변수 비교 3. 요금(Fare), 성별(Sex), 승선항(Embarked)
grid = sns.FacetGrid(train, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()
C가 요금이 제일 높았고, 위에서 살펴보았을 때 C가 생존률이 제일 높았다.
S가 그 다음이고, Q가 마지막이었다.
그리고 생존한 사람들의 요금이 사망한 사람들의 요금보다 더 높은 것을 확인했다.
아까 요금을 보니 7도 있고 70도 있던데.. 요금 격차가 매우 크다.
셰르부르가 부촌이었나보다..
다중변수 비교 4. 승선항(Embarked), 객실등급(PClass)
S = train[train['Embarked'] == 'S']['Pclass'].value_counts()
C = train[train['Embarked'] == 'C']['Pclass'].value_counts()
Q = train[train['Embarked'] == 'Q']['Pclass'].value_counts()
df = pd.DataFrame([S, C, Q])
df.index = ['S', 'C', 'Q']
df.plot(kind='bar', stacked=True셰르부르가 부촌인지 확인해보기 위해 객실등급과 비교했다.

예상대로 셰르부르는 부촌이었다. C의 거의 절반을 차지하고 있는 것을 보아서
셰르부르에서 탈수록 객실등급이 높을 가능성이 컸다.
S 사우샘프턴은 가장 사람이 많이 탄 만큼 전체적인 비율과 비슷한 것을 볼 수 있고,
Q 퀸즈타운은 3등급이 많은 것을 확인할 수 있다.
각 데이터들 간의 상관관계를 알아보자.
sns.heatmap(train.corr(),annot=True,cmap='RdYlGn',linewidths=0.2)
fig=plt.gcf()
fig.set_size_inches(10,8)
plt.show()
양이던 음이던 Fare와 PClass는 확실히 관계가 있는 것으로 보인다.
다른 눈에 띄는 상관관계는 보이지 않는다.
생존과 Passengerid는 관계가 거의 없어 보인다.
변수들의 특징
- PassengerId : 상관없는 변수일 것으로 추정. 날린다.
- Name : 숫자 범주형 변수로 바꾸어준다.
- Pclass : 1등석 > 2등석 > 3등석 순으로 생존률이 높은 것을 확인.
- Sex : Female 여성일수록 생존률이 높은 것을 확인.
- Age : 영유아(0-10세)일수록 생존률이 높은 것을 확인.
- SibSp : 형제자매 수가 적을수록 생존률이 높은 것을 확인.
- Parch : 마찬가지로 적을수록 생존률이 높은 것을 확인.
- Ticket : 티켓 번호 - 관계가 없는 변수일 것으로 추정. 날린다.
- Fare : 요금이 높을수록 생존률이 높은 것을 확인.
- Cabin : 방 호수 - 관계가 없는 변수일 것으로 추정. 결측치도 너무 많다. 날리자
- Embarked : 탑승지, C = 셰르부르, Q = 퀸즈타운, S = 사우샘프턴 . C 셰르부르 > Q 퀸즈타운 > S 사우샘프턴 순으로 생존률이 높았다.
데이터 전처리
필요없는 Ticket, Cabin 을 제거해준다.
print("Before", train.shape, test.shape)
train= train.drop(['Ticket', 'Cabin'], axis=1)
test= test.drop(['Ticket', 'Cabin'], axis=1)
combine = [train, test]
print("After", train.shape, test.shape)Before (891, 12) (418, 11)
After (891, 10) (418, 9)칼럼 2개가 삭제되었다.
범주형 변수로 변환을 해야 하므로 Title 이라는 칼럼을 만들어주고, 정규식과 성별을 합쳐서
범주를 본다.
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
print(pd.crosstab(train['Title'], train['Sex']))Sex female male
Title
Capt 0 1
Col 0 2
Countess 1 0
Don 0 1
Dr 1 6
Jonkheer 0 1
Lady 1 0
Major 0 2
Master 0 40
Miss 182 0
Mlle 2 0
Mme 1 0
Mr 0 517
Mrs 125 0
Ms 1 0
Rev 0 6
Sir 0 1여성은 Countess, Dr, Lacy, Miss, Mlle, Mme, Mrs, Ms 가 있었고
남성은 Capt, Col, Don, Dr, Jonkheer, Major, Master, Mr, Rev, Sir 가 있었다.
여성에서는 Miss와 Mrs, 남성에서는 Master 와 Mr 가 눈에 띈다.
나머지는 Rare로 분류해준다.
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\
'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
print(train[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()) Title Survived
0 Master 0.575000
1 Miss 0.702703
2 Mr 0.156673
3 Mrs 0.793651
4 Rare 0.347826여성인 Miss 와 Mrs 의 생존률이 70%가 넘는 것으로 높게 나타났다.
이제 이를 숫자형 변수로 바꾸어준다.
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
print(train.head()) PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Fare Embarked Title
0 0 7.2500 S 1
1 0 71.2833 C 3
2 0 7.9250 S 2
3 0 53.1000 S 3
4 0 8.0500 S 1 
Title 이라는 칼럼이 나타난 것을 볼 수 있다.
이제 Name 은 삭제해주자.
삭제하면서 , PassengerID 도 같이 날려주자.
train = train.drop(['Name', 'PassengerId'], axis=1)
test = test.drop(['Name'], axis=1)
combine = [train, test]
#test데이터셋에는 PassegnerId변수가 없습니다.
print(train.shape, test.shape)(891, 9) (418, 9)
성별 변수 또한 원핫인코딩을 사용하여 0과 1로 바꾸어준다.
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
print(train.head())
이제 남은 것은 Age, Embarked 의 결측값 처리.
EDA에서 살펴보았을 때 Age가 왼쪽으로 치우처져있는 것을 보았기 때문에,
평균값이 아닌 중앙값으로 대체해야겠다.
train.isnull().sum()Survived 0
Pclass 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
Embarked 2
Title 0
dtype: int64train.median()Survived 0.0000
Pclass 3.0000
Sex 0.0000
Age 28.0000
SibSp 0.0000
Parch 0.0000
Fare 14.4542
Title 1.0000
dtype: float64Age 의 중앙값은 28. 28로 대체해주자.
train['Age'] = train['Age'].fillna(28)
train.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Survived 891 non-null int64
1 Pclass 891 non-null int64
2 Sex 891 non-null int32
3 Age 891 non-null float64
4 SibSp 891 non-null int64
5 Parch 891 non-null int64
6 Fare 891 non-null float64
7 Embarked 889 non-null object
8 Title 891 non-null int64
dtypes: float64(2), int32(1), int64(5), object(1)
memory usage: 59.3+ KBAge의 결측치가 채워졌다.
다음은 Embarked 의 결측치를 채워야하는데, 결측치가 2개밖에 안 되니
그냥 최빈값으로 채워주자.
freq_port = train.Embarked.dropna().mode()[0] # "S"
for dataset in combine:
dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
이제 나이를 5개 그룹으로 쪼개서 범주형으로 만들어주자.
AgeBand 를 만들어 그룹을 만들어준다.
train['AgeBand'] = pd.cut(train['Age'], 5)
#임의로 5개의 그룹을 지정합니다.
print(train[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)) AgeBand Survived
0 (0.34, 16.336] 0.550000
1 (16.336, 32.252] 0.344168
2 (32.252, 48.168] 0.404255
3 (48.168, 64.084] 0.434783
4 (64.084, 80.0] 0.090909나누어졌다. 확실히 AgeBand 가 영유아인 그룹이 생존률이 높다.
그룹을 칼럼으로 만들어서 넣어주자.
for dataset in combine:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age']
train = train.drop(['AgeBand'], axis=1)
combine = [train, test]
print(train.head()) Survived Pclass Sex Age SibSp Parch Fare Embarked Title
0 0 3 0 1.0 1 0 7.2500 0 1
1 1 1 1 2.0 1 0 71.2833 1 3
2 1 3 1 1.0 0 0 7.9250 0 2
3 1 1 1 2.0 1 0 53.1000 0 3
4 0 3 0 2.0 0 0 8.0500 0 1추가로 Age와 Pclass 를 곱해서 변수를 하나 더 만들어준다.
Pclass 와 결합했을 때, Age의 생존 여부에 대한 설명력이 증가한 것에 근거했다고 추측이 가능하다.
for dataset in combine:
dataset['Age*Class'] = dataset.Age * dataset.Pclass
print(train.loc[:, ['Age*Class', 'Age', 'Pclass']].head(3)) Age*Class Age Pclass
0 3.0 1.0 3
1 2.0 2.0 1
2 3.0 1.0 3
Sibsp와 Parch 를 합쳐서 똑같이 범주형으로 나누어준다.
Family Size 로 만들어 쪼개준다.
for dataset in combine:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
#자기 자신을 포함시킵니다.
print(train[['FamilySize', 'Survived']].groupby(['FamilySize'],
as_index=False).mean().sort_values(by='Survived', ascending=False)) FamilySize Survived
3 4 0.724138
2 3 0.578431
1 2 0.552795
6 7 0.333333
0 1 0.303538
4 5 0.200000
5 6 0.136364
7 8 0.000000
8 11 0.000000가족 3명인 그룹은 72퍼센트가 살아남았다.
for dataset in combine:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
print(train[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()) IsAlone Survived
0 0 0.505650
1 1 0.303538혼자 온 사람은 0, 가족이 있는 사람은 1이다.
train = train.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test = test.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train, test]
요금도 범주형으로 쪼개준다.
train['FareBand'] = pd.qcut(train['Fare'], 4)
print(train[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)) FareBand Survived
0 (-0.001, 7.91] 0.197309
1 (7.91, 14.454] 0.303571
2 (14.454, 31.0] 0.454955
3 (31.0, 512.329] 0.581081test['Fare'].fillna(test['Fare'].dropna().median(), inplace=True)결측치는 중앙값으로 대체해주고,
for dataset in combine:
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
train = train.drop(['FareBand'], axis=1)결합
train.head()
전처리 데이터프레임이 완성됐다 !
모델 학습
총 5개의 모델을 학습시켜 적용시켜본다.
- Logistic Regression
- Support Vector Machine (SVM)
- k-Nearest Neighbor (kNN)
- Random Forest
- Naive Bayes
로지스틱 회귀, 서포트 벡터 머신, KNN, 랜덤포레스트, 나이브 베이즈.
분류모델이다. 생존, 사망 2가지로 분류해야 하기 때문에 분류 모델들을 적용시킨다.
# One-hot-encoding for categorical variables
train = pd.get_dummies(train)
test = pd.get_dummies(test)
train_label = train['Survived']
train_data = train.drop('Survived', axis=1)
test_data = test.drop("PassengerId", axis=1).copy()레이블과 train, test데이터를 분리해준다.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.utils import shuffle사이킷런에서 라이브러리들을 불러온다.
학습 전에, 데이터들을 한 번 섞어준다.
train_data, train_label = shuffle(train_data, train_label, random_state = 5)def train_and_test(model):
model.fit(train_data, train_label)
prediction = model.predict(test_data)
accuracy = round(model.score(train_data, train_label) * 100, 2)
print("Accuracy : ", accuracy, "%")
return prediction함수를 정의해주고,
학습시켜준다.
# Logistic Regression
log_pred = train_and_test(LogisticRegression())
# SVM
svm_pred = train_and_test(SVC())
#kNN
knn_pred_4 = train_and_test(KNeighborsClassifier(n_neighbors = 4))
# Random Forest
rf_pred = train_and_test(RandomForestClassifier(n_estimators=100))
# Navie Bayes
nb_pred = train_and_test(GaussianNB())Accuracy : 80.36 %
Accuracy : 78.56 %
Accuracy : 83.16 %
Accuracy : 84.29 %
Accuracy : 72.17 %랜덤포레스트 모델이 84%로 가장 높은 정확도를 보였다.
근데 별로 좋은 모델은 아닌 것 같다.
여러가지를 조잡하게 따라하다 보니 오히려 원본들보다 정확도가 떨어졌다.
힝 ..
도움받은 분들
말이 도움이지 그대로 따라한 것이나 다름이 없음.
https://cyc1am3n.github.io/2018/10/09/my-first-kaggle-competition_titanic.html
캐글 타이타닉 생존자 예측 도전기 (1)
이번에는 캐글의 입문자를 위한 튜토리얼 문제라고 할 수 있는 Titanic: Machine Learning from Disaster 의 예측 모델을 python으로 풀어보는 과정에 대해서 포스트를 할 것이다.
cyc1am3n.github.io
https://data-science-note.tistory.com/4
Kaggle 타이타닉(문제 정의~데이터 전처리)
데이터 분석 코드 필사 (2020.07.22)¶ - 원본: Titanic Data Science Solutions (by Manav Sehgal)¶ - 순서¶ 1. 문제 정의¶ 2. 훈련, 테스트 자료 정의¶ 3. 데이터 분석¶ 4. 데이터 전처리¶ 문제 정의¶ 19..
data-science-note.tistory.com
https://todo-data.tistory.com/4?category=842819
Kaggle 캐글 연습#1_Titanic 타이타닉 생존자 예측_2/2
※데이터 전처리는 이전 포스팅에 개재 2019/05/06 - [데이터분석/분석 연습] - Kaggle 캐글 연습#1_Titanic 타이타닉 생존자 예측_1/2 데이터 전처리 데이터 준비 데이터 변수(feature)확인 탐색적 데이터
todo-data.tistory.com
https://www.kaggle.com/code/startupsci/titanic-data-science-solutions/notebook
Titanic Data Science Solutions
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
[머신러닝 기초] 타이타닉 생존율 분석 - EDA #1 데이터 내용 및 객실등급(Pclass), 성별(Sex)확인
머신러닝을 시작할 때 많이 참조하는 타이타닉 생존율 분석을 통해서 어떻게 머신러닝을 사용할 수 있고, 데이터는 어떻게 가공하고 분석하는지, 머신러닝 모델은 어떻게 사용하는지 등을 초보
www.kangtaeho.com
[Keras] 타이타닉 생존자 분석. 디카프리오는 정말 살 수 없었을까?
영화 타이타닉의 감동을 이번 공부를 하면서 느꼈네요. 머신러닝을 공부하는 분들이 항상 수행하는 연습문제로 MNIST 필기 숫자 인식과 함께 타이타닉 생존자 분석이 있습니다. 저도 역시 공부하
pinkwink.kr



