
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- ML
- datascience
- 오버샘플링
- DL
- ADsP3과목
- 머신러닝
- 텍스트마이닝
- 2023공공빅데이터청년인재양성
- machinelearning
- 2023공빅데
- SQL
- Keras
- NLP
- 클러스터링
- 공공빅데이터청년인턴
- data
- 공빅데
- textmining
- DeepLearning
- k-means
- 빅데이터
- 공공빅데이터청년인재양성
- 분석변수처리
- Kaggle
- decisiontree
- 데이터분석
- 2023공공빅데이터청년인재양성후기
- 공빅
- ADSP
- 데이터전처리
- Today
- Total
愛林
[Python/DL] 합성곱 신경망 (Convolution Neural Network) :: CNN 본문
[Python/DL] 합성곱 신경망 (Convolution Neural Network) :: CNN
愛林 2023. 2. 2. 10:55합성곱 신경망 (Convolution Neural Network, CNN)
여러 딥러닝 모델들 중 특히나 이미지 처리에 성능이 좋은 다층 신경망이다.
인공신경망의 부흥기인 1995년에 LeCun과 Bengio가 CNN (Convolution Neural Network) 을 발표했다.
이를 이용해서 문자 인식이나 음성 인식에는 아주 좋은 성능이 발휘되었지만, 기존 신경망이 가졌던 문제들이
해결되지 않은 시점이었기에 SVM 등의 알고리즘에 밀렸었다.
이후 딥러닝이라는 기술이 나오며 기존 인공신경망이 가졌던 문제들이 해결되며 CNN도 강력해졌다.
현재는 이미지 분류에서는 최강의 성능을 보이고 있으며 CNN 과 유사한 신경망들도 많이 개발되어
이 알고리즘의 활용성이 많이 높아진 상태이다.

CNN 은 위의 사진의 디저트와 개, 고양이를 잘 구별해낸다.
CNN 이 단순한 인공신경망과 다른 점은,
FNN은 모든 입력이 위치와 상관 없이 동일한 수준의 중요도를 갖고 있기 때문에 이미지 분류에 FNN 를 사용한다면
파라미터의 크기가 엄청나게 커지는 문제가 발생한다. 이는 이미지의 형상을 고려하지 않는 1차원 연산이다.
그래서 이미지가 회전하거나 조금이라도 달라지면 새로운 입력으로 데이터를 처리해주어야 하기에 학습 시간 또한 길어진다.
또한 이미지는 인접 픽셀간의 관계가 매우 중요한데, FNN은 1차원적 연산이기에 이를 위해 이미지를 1차원 벡터로 변환시키는 과정에서 막대한 정보 손실이 발생한다.

CNN 은 이런 신경망에 기존의 필터 기술을 병합하여 각 픽셀마다 중요도를 다르게 주는 방식으로 신경망이 2차원 영상을 잘 습득할 수 있도록 최적화시키고, 위치 정보까지 보존시키므로 이미지 분석에 탁월하다.
합성곱 신경망은 크게 합성곱층(Convolution lyaer) 와 풀링층(Pooling layer) 로 구분된다.

위 사진에서 CONV가 합성곱 연산이다. 그리고 이 합성곱 연산의 결과는 이전에 배웠던 인공신경망처럼
활성화함수(사진에서는 ReLu) 를 지난다. 이 두 과정을 합성곱층이라고 한다.
이후 POOL 이라고 되어있는 부분이 풀링층이다. 여기에서는 풀링 연산을 수행한다.
이후 FC (Fully Connected) 계층에서 필터링된 이미지에 대한 분류연산이 수행된다.
합성곱 층은 이미지에 필터링 기법들이 적용되고, 풀링 계층은 이미지의 국소적인 부분들을 하나의 대표적인 스칼라 값으로 변환함으로써 이미지의 크기를 줄이는 등의 다양한 기능들을 수행한다. 이후 Fully Connected Layer 에서 연산을 수행하고 결과를 얻어낸다.
한 마디로 CNN = 합성곱(Convolution)[특징추출단계] + 일반적인 신경망[분류 단계] 이다.
여기서 이미지 처리에 기본적인 용어인 채널(Channel) 에 대해서 간략하게 설명하고 넘어가보자.
기계는 글자나 이미지 같은 비정형 데이터보다 정형적인 숫자 데이터. (여기서는 텐서(Tensor) 라고 부른다.)
이를 더 잘 처리한다.
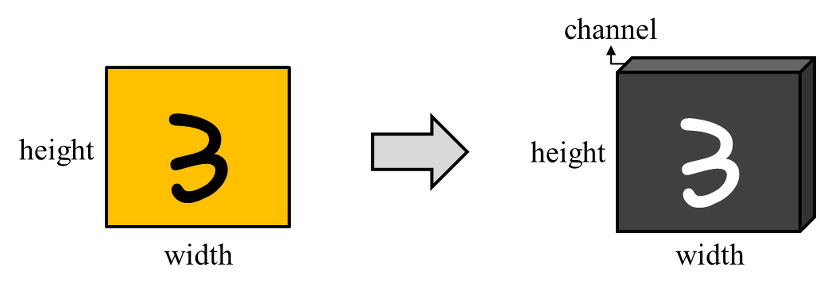
이미지는 (높이,너비,채널) 이라는 3차원 텐서이다. 높이는 세로, 너비는 가로 픽셀수, 채널은 색을 나타낸다.
채널은 때로는 깊이(Depth) 라고도 한다.
흑백 이미지는 채널의 수가 1이며, 각 픽셀은 0부터 255 사이의 값을 갖는다.
아래는 28 x 28 픽셀의 손글씨 데이터이다.

위는 (28 x 28 x 1) 의 크기를 가지는 3차원 Tensor이다.
합성곱 (Convolution)
위에서 말했듯, 합성곱층은 해당 이미지의 특성을 추출하는 역할을 한다. 컨벌루션이라고 부르며,
이는 커널(Kernal) 혹은 필터(Filter) , 윈도우(window) 라고도 한다.
아무튼 이러한 n x m 크기의 행렬로 이미지를 처음부터 끝까지 겹치며 훑으면서
n x m 크기의 겹쳐지는 각 이미지와 커널의 원소값을 곱해서 모두 더한 것을 출력으로 하는 것을 말한다.
이런 2차원 합성곱 연산을 2D 합성곱연산(2D Convolutions) 라고 부른다.
일반적으로 커널은 3 x 3 , 5 x 5 를 사용한다.
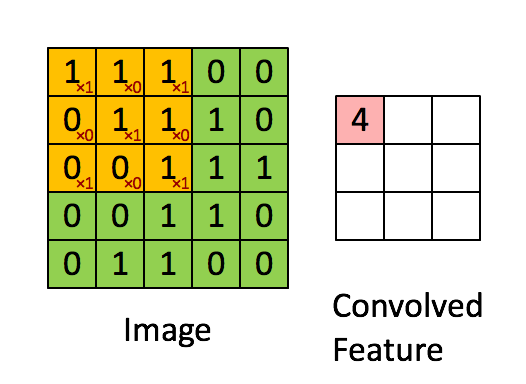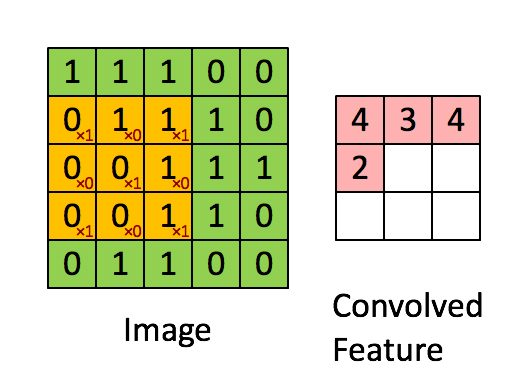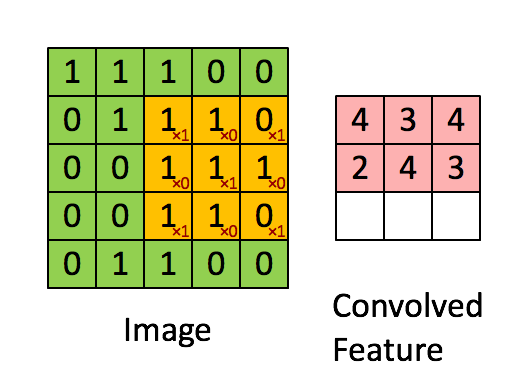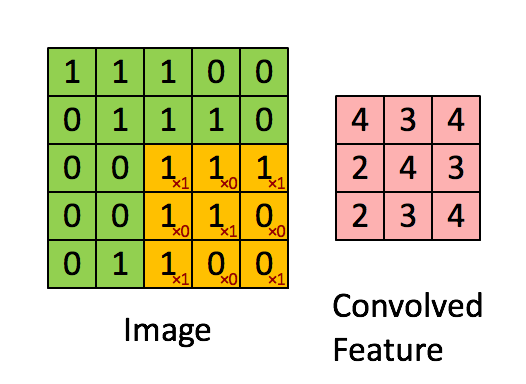
위에서 말한 걸 이미지로 본다면 위와 같다.
이를 분리해내서 보면 아래와 같다.

위에선 1칸씩 이동하면서 연산을 수행하는데, 몇 칸을 이동할 지도 사용하는 사람이 설정할 수 있다.
이런 이동량을 스트라이드(stride) 라고 한다. 보통은 1로 설정된다.
위와 같이 Filter(=Kernal) 을 이용해서 연산하는 게 합성곱 연산이며 이 연산으로 나온 결과(Convolved Feature) 를
특성 맵 (Feature map) 이라고 한다.
뭔가 살펴보니 이전에 배웠던 신경망에 가중치를 곱해서 더하는 것과 유사하다.
조금 더 상세하게 설명해보자면,
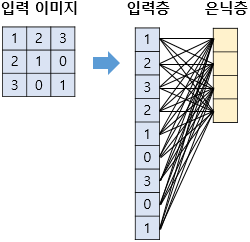
입력 이미지를 인공 신경망으로 구현한다면 위와 같다.
입력층은 입력이미지의 픽셀이므로 1차원으로 표현한다. 이후 가중치가 곱해져 4개의 뉴런을 갖는 은닉층으로
보내진다. 입력층이 은닉층으로 갈 때, 가중치인 w가 곱해졌었다.
이를 비교하여 같은 입력 이미지를 합성곱으로 표현하면 아래와 같다.
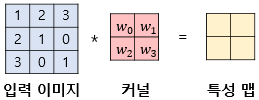
입력이미지 픽셀 값에 커널의 4개값을 곱해서 더하면 특성맵의 픽셀 하나가 된다.
가중치를 곱해서 더하는 인공신경망과 방식이 유사하다.
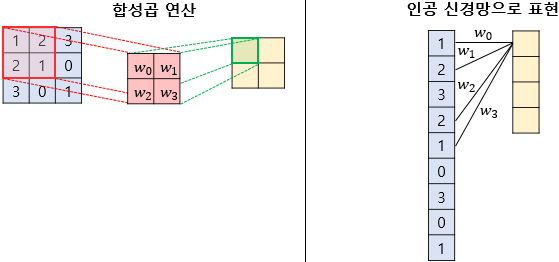
사실상 kernal이 인공신경망의 가중치의 역할을하게 되는 셈이다.
최종적으로 특성맵을 얻기 위해서는 동일한 커널로 이미지 전체 픽셀을 훑으며 합성곱 연산을 수행한다.
가중치 4개로 이미지 전체를 훑게 된다.
각 합성곱 연산마다 이미지의 모든 픽셀을 사용하는 게 아니라 커널과 맵핑되는 픽셀만을 입력으로 사용한다.
그러므로 합성곱 신경망은 인공신경망보다 더 적은 수의 가중치를 이용하여 공간적 구조 정보를 보존한다.
여기에 편향을 추가하는 것 또한 가능하다.
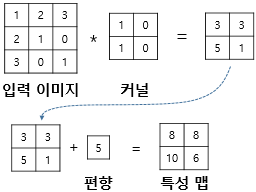
최종 값에 편향값 한 개를 모든 픽셀에 더해주면 된다.
다시 합성곱 연산으로 돌아와서,
아래는 스트라이드가 2일 경우에 5 x 5 이미지에 3 x 3 커널을 적용하여 합성곱 연산을 수행하는 것이다.
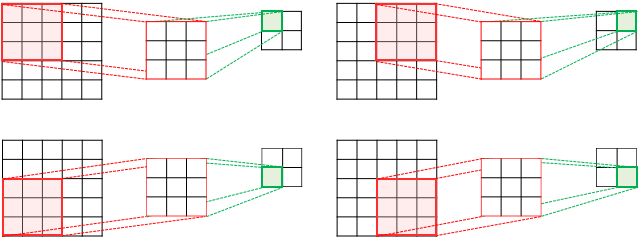
최종 연산 결과 , 2 x 2 의 특성맵이 추출되었다.
패딩 (padding)
위 연산에서, 5x5 이미지에 3x3 윈도우를 1 스트라이드로 연산했을 때 결과값이 2x2 가 나왔다.
이와 같이 합성곱 연산은 그 결과값이 입력값보다 크기가 작아진다는 특징이 있다.
만약, 합성곱 층을 여러개 쌓았다고 한다면 최종적인 특성 맵은 초기 입력보다 매우 작아질 것이다.
합성곱 연산 이후에도 특성 맵의 크기가 입력의 크기와 동일하게 유지되도록 하고 싶다면, 패딩(padding) 을 이용하면 된다.
텍스트 처리에서 하는 그 패딩과 똑같다.
이미지 처리에선 합성곱 연산을 하기 전 input 값 가장자리에 지정된 개수의 열과 행을 추가해주면 된다.
테두리를 추가하는 것이다.
보통은 테두리에 0을 두르는 형태로 진행하는데, 이를 제로 패딩(zero padding) 이라고 한다.

스트라이드가 1이라고 했을 때, 내가 3 x 3 의 커널을 사용한다면 1폭짜리 제로 패딩을 진행 해주고,
5 x 5 커널을 이용한다면 2폭짜리 제로 패딩을 진행해주면 입력과 특성맵의 크기를 동일하게 유지할 수 있다.

CNN 에서는 보통 이러한 제로 패딩이 많이 수행된다.
특성 맵의 크기는 식으로도 계산할 수 있다.

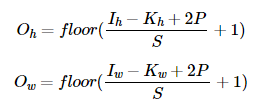
P는 패딩의 폭이다.
풀링 (Pooling)
일반적인 CNN 에서 합성곱 층 다음에는 풀링층이 온다.
풀링 층에서는 특성 맵을 다운 샘플링 (Down Sampling) 하여 특성 맵의 크기를 줄인다.
풀링 연산에서는 일반적으로 최대 풀링(Max Pooling) 과 평균 풀링(Average Pooling) 이 사용된다.
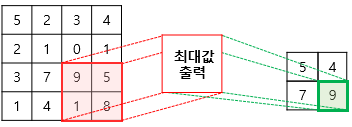
최대 풀링(Max Pooling) 은 이와 같다.
최대값을 도출해내는데 이는 뉴런이 가장 큰 신호에 반응하는 것과 유사하다.
위 그림은 스트라이드가 2일 때 2x2 크기 커널로 맥스 풀링 연산을 했을 때 특성 맵이 절반의 크기로
다운 샘플링 되는 것을 확인 할 수 있다.
스트라이드가 1이면 3x3 크기로 다운샘플링 되는 커널이 되겠다.
평균 풀링은 저기에서 그냥 최대값이 아닌 평균값을 구하는 것이다.
풀링은 합성곱 연산과 비슷하지만, 학습할 가중치가 없고 연산 후 채널 수(깊이) 가 변하지 않는다는 것이 차별점이다.
참고
11-01 합성곱 신경망(Convolution Neural Network)
합성곱 신경망(Convolutional Neural Network)은 이미지 처리에 탁월한 성능을 보이는 신경망입니다. 하지만 합성곱 신경망으로 텍스트 처리를 하기 위한 시도들이…
wikidocs.net
https://untitledtblog.tistory.com/150
[머신 러닝/딥 러닝] 합성곱 신경망 (Convolutional Neural Network, CNN)과 학습 알고리즘
1. 이미지 처리와 필터링 기법 필터링은 이미지 처리 분야에서 광범위하게 이용되고 있는 기법으로써, 이미지에서 테두리 부분을 추출하거나 이미지를 흐릿하게 만드는 등의 기능을 수행하기
untitledtblog.tistory.com
https://ko.wikipedia.org/wiki/%ED%95%A9%EC%84%B1%EA%B3%B1_%EC%8B%A0%EA%B2%BD%EB%A7%9D
합성곱 신경망 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 합성곱 신경망(콘볼루션 신경망, Convolutional neural network, CNN)은 시각적 영상을 분석하는 데 사용되는 다층의 피드-포워드적인 인공신경망의 한 종류이다. 필터링
ko.wikipedia.org
https://m.blog.naver.com/msnayana/220776380373
컨벌루션 신경망 ( Convolutional Neural Networks, CNN ) ~ 개요
컨벌루션 신경망 ( Convolutional Neural Networks, CNN ) ~ 개요 딥러닝 알고리즘중에서 영상...
blog.naver.com
https://gruuuuu.github.io/machine-learning/cnn-doc/
호다닥 공부해보는 CNN(Convolutional Neural Networks)
CNN? CNN은 이미지를 인식하기위해 패턴을 찾는데 특히 유용합니다. 데이터에서 직접 학습하고 패턴을 사용해 이미지를 분류합니다. 즉, 특징을 수동으로 추출할 필요가 없습니다. 이러한 장점때
gruuuuu.github.io
'Data Science > Deep Learninng' 카테고리의 다른 글
| [Python/DL] 딥 러닝 (Deep Learning) - Keras (3) | 2023.01.12 |
|---|---|
| [Python/DL] 딥 러닝 (Deep Learning) (3) - 역전파(BackPropagation) (3) | 2023.01.12 |
| [Python/DL] 딥 러닝 (Deep Learning) (2) - 딥 러닝(Deep Learning) 의 학습 (3) | 2023.01.10 |
| [Python/DL] 딥 러닝 (Deep Learning) (1) - 퍼셉트론(Perceptron)과 신경망 (2) | 2023.01.10 |
| [Python/DL] 분류 알고리즘 (Classification Algorithm) : 인공신경망 (ANN : Article Neural Network) - (2) (2) | 2022.12.09 |



