
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 머신러닝
- ADSP
- machinelearning
- ML
- decisiontree
- 오버샘플링
- 클러스터링
- SQL
- textmining
- NLP
- 데이터전처리
- k-means
- 분석변수처리
- data
- 공공빅데이터청년인재양성
- 빅데이터
- 공공빅데이터청년인턴
- Kaggle
- DL
- datascience
- 데이터분석
- 2023공공빅데이터청년인재양성후기
- Keras
- 텍스트마이닝
- 2023공공빅데이터청년인재양성
- ADsP3과목
- DeepLearning
- 공빅데
- 공빅
- 2023공빅데
- Today
- Total
愛林
[Python/MachineLearning] Decision Tree(의사결정나무) 본문
Decision Tree (의사결정나무)
의사결정트리는, 데이터들이 가진 속성들로부터 분할 기준 속성을 판별하고,
분할 기준 속성에따라서 트리 형태로 모델링하는 분류 및 예측 모델이다.
불순도와 순수도, 트리 깊이(Depth) 를 설정한다.
의사결정나무는 나무 구조에 의해서 모델이 표현되기 때문에 해석이 쉬우며,
새로운 자료에 모델을 적합시키기가 쉽다. 두 개 이상의 변수가 결합하여 종속변수에 어떠한 영향을
주는 지에 대해 알기가 쉽다. 그리고 이상치에 또한 민감하지 않다.
그러나, 연속형 변수를 비연속적인 값으로 취급하기 때문에 예측 오류가 클 가능성이 높다.
그리고 선형 또는 주 효과 모델에서와 같은 결과를 얻을 수 없고 분석용 자료에만 의존하기 때문에
새로운 자료의 예측에는 불안정한 모습을 보인다.
의사결정나무의 형성 과정
1. 변수를 선택한다. : 종속변수와 관계가 있는 독립변수를 선택한다.
2. 분석 목적과 자료의 구조에 따라서 적절한 분리 기준과 정지규칙을 정하여 의사결정나무의 구조를 작성한다.
CHAID, CART, C4.5 등의 알고리즘을 사용할 수 있고,
분리 규칙과 분리 기준, 그리고 정지 규칙을 설정한다.
분리 규칙 : 불순도 감소량을 가장 크게 하는 분할, 최적 분리 기준을 찾은 후각 분할에 대해서 반복한다.
분리 기준 : 불순도에 이ㅡ해 측정된다. 종속변수의 특정 범주에 개체들이 포함되어 있는 정도를 말한다.
정지 규칙 : 더 이상 분리가 일어나지 않고 마디가 끝나도록 Depth 를 지정한다. 불순도 감소량이 작을 때를 설정
3. 가지치기 : 부적절한 가지를 제거한다.
4. 타당성 평가 : 이익, 위험, 비용 등을 고려해서 모델을 평가한다.
5. 분류 및 예측을 수행한다.
불순도 (Impurity) 와 순수도(Purity) 는 마디의 분리 기준이다.
불순도란, 다양한 범주들의 개체들이 얼마나 포함되어 있는가를 의미한다.
순수도는 목표 변수의 특정 범주에 개체들이 포함되어 있는 정도를 말한다.
부모 마디의 순수도에 비해서 자식 마디들의 순수도가 증가하도록 자식 마디를 형성해야 한다.
즉, 부모 마디는 불순도가 높고, 자식 마디는 순수도가 높아진다.


분류 나무 ( Classification Tree)
종속변수가 범주형이다.
1. 카이제곱 통계량
카이제곱 통계량이 자유도에 비해서 매우 작다는 것은 예측변수의 각 범주에 따른 목표변수의 분포가
서로 동일하다는 것을 의미한다. 예측변수가 목표 변수의 분류에 영향을 주지 않는다고 결론짓는 것이다.
귀무가설 : 두 개의 노드 간의 A, B의 구성 비율이 동일하다.
p-vlaiue 가 작을수록 자식 노드 간의 이질성이 크다. = > 분류가 잘 된 것이다.
자식 노드 간의 이질성이 클수록 다른 것끼리 분류를 잘 한 것이 되기 때문에 좋은 모델이 된다.
2. 지니지수
경제적 불평등을 표현하는 방법으로, 지니계수가 1에 가까울수록 소수의 사람이 다 해먹는 것을 의미.
0에 가까울수록 평등함을 의미한다.
0에 가까울수록 그 클래스에 속한 불순도가 낮다. 이것은 좋은 분리 기준이 된다.
지니지수가 0.5 일 때 불순도가 높다 = 이질성이 높다 = 순수도가 낮다.
3. 엔트로피
엔트로피값이 높을수록 불순도가 높으며, 불순도가 클수록 자식 노드 내의 이질성이 큰 것을 의미한다.
엔트로피 값이 작아지는 방향으로 분리해야 한다.
엔트로피 지수의 범위는 0~1 사이이며, 0에 가까울수록 노드 내의 데이터들이 동질적임을 의미한다.
회귀 나무 ( Regression Tree)
종속변수가 연속형인 경우이다.
각 지표 값이 작아지는 값으로 범주를 선택한다.
부모 노드의 평균제곱오차를 가장 많이 감소시키는 설명변수와 분리 값을 기준으로
자식 노드를 생성한다.
MSE (평균제곱오차) 가 작을수록 오차가 작은 좋은 모델이다.

R^2 는 결정계수로 회귀 모델이 실제 데이터와 얼마나 잘 맞는지를 측정한다.
0부터 1까지의 범위에서 측정한다. 1에 가까울수록 좋은 모델임을 의미한다.

의사결정나무 실습
위에서 배운 의사결정나무를 실습해보자.
sklearn 에서 tree 를 불러와주고,
tree 에서 DecisionTreeClassifier 를 불러오자.
- crierion (str) : 정보량 계산 시에 사용할 수식 (gini/entropy)
- max_depth (int) : 생성할 트리의 높이 (깊이)
- min_samples_split (int) : 분기를 수행하는 최소한의 데이터 수
- max_leaf_nodes (int) : 리프 노드가 가지고 있을 수 있는 최대 데이터의 수
- random_state (int) : 내부적으로 사용되는 난수 값
import warnings
warnings.simplefilter(action = 'ignore', category = FutureWarning)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.model_selection import train_test_split각종 함수와 나중에 점검할 때 사용할 혼동행렬, 정확도, classification report 도 불러와주자
tree 시각화에 필요한 graphviz 를 설치해주고, 불러와주자.
이거 그냥 하면 잘 안 돼서 경로설정을 해줘야 한다.
경로설정도 까다롭긴 한데 ..
에러가 날 시 :)
사실 구글링이 정확하긴 하지만, 내 방법을 간략하게 말해주자면
나는 아나콘다를 이용해서 설치해주었다.
아나콘다 프롬프트 창에서 pip install graphviz .
그리고 graphviz 안에 bin 파일이 들어있는 graphviz 폴더를 통째로 Program 으로 옮기고,
아래처럼 경로설정을 해주니 정상적으로 실행되었다.
## sklearn 모듈의 tree import
from sklearn import tree
# tree 시각화
import graphviz as gv
from sklearn.tree import export_graphviz
import os
# 환경변수 추가 후 환경변수 설정 아래 코드
os.environ["PATH"]+= os.pathsep + 'C:/Program Files/Graphviz/bin'
에러 없이 정상적으로 실행된다면 넘어가도 된다.
## 테스트 데이터 생성
# 성별 남 : 0, 여 : 1
my_list1 = [
'0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0',
'0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0',
'1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0',
'1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1',
'1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1' ]
# 나이
my_list2 = [50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30,
30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50,
50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30,
30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30]
# 타겟 데이터, good/bad : good(0),bad(1)
my_list3 = ['0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0',
'0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '0',
'0', '0', '0', '0', '0', '0', '0', '0', '0', '0', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1',
'1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1',
'1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1', '1' ]
df_tree_t = pd.DataFrame({'성별': my_list1,
'나이': my_list2,
'good/bad': my_list3})데이터를 만들어주었다.
# 데이터 확인
print(df_tree_t.shape)
print(df_tree_t.info())
df_tree_t.head(3)
데이터를 컨버전 시켜서 우리가 원하는 대로 만들어주자.
나이 기준으로 먼저 해보자.
지니계수 사용
나이기준
# 지니지수 -- 나이기준
# 데이터 컨버전
train_temp_X = np.array(df_tree_t['나이'])
train_temp_X = train_temp_X.reshape(-1,1)
train_temp_y = np.array(df_tree_t['good/bad'])
train_temp_y = train_temp_y.reshape(-1,1)

criterion = "gini" .
지니계수로 표현한 의사결정트리 모델을 피팅시켜주자.
지니계수는 0에 가까울수록 그 클래스에 속한 불순도가 낮다.
순수하다는 의미이다.
지니계수가 0.5이면 불순도가 높다.
# 지니지수의 의사결정트리 모델 피팅
gini_clf = tree.DecisionTreeClassifier(criterion = "gini", max_depth = 3,
random_state= 20 )
gini_clf = gini_clf.fit(train_temp_X, train_temp_y)
# 시각화
dot_data = tree.export_graphviz(gini_clf, # 의사결정나무 모델 대입
out_file = None, #file 로 변환할 것인가
feature_names = ['나이'], #feature이름
class_names = ['good', 'bad'], #target 이름
filled = True, # 그림에 색상을 넣을 것인가)
rounded = True, # 반올림 할 것인가
special_characters = True) # 특수문자를 사용할 것인가
graph = gv.Source(dot_data)
graph깊이는 3으로 주었다.

성별 기준
# 지니지수 -- 성별기준
train_temp_X = np.array(df_tree_t['성별'])
train_temp_X = train_temp_X.reshape(-1,1)
train_temp_y = np.array(df_tree_t['good/bad'])
train_temp_y = train_temp_y.reshape(-1,1)# 지니지수의 의사결정트리 모델 피팅
gini_clf = tree.DecisionTreeClassifier(criterion = "gini", max_depth = 3,
random_state= 20 )
gini_clf = gini_clf.fit(train_temp_X, train_temp_y)
# 시각화
dot_data = tree.export_graphviz(gini_clf, # 의사결정나무 모델 대입
out_file = None, #file 로 변환할 것인가
feature_names = ['성별'], #feature이름
class_names = ['good', 'bad'], #target 이름
filled = True, # 그림에 색상을 넣을 것인가)
rounded = True, # 반올림 할 것인가
special_characters = True) # 특수문자를 사용할 것인가
graph = gv.Source(dot_data)
graph
성별로 분류했을 때 순수도가 높아진 것을 볼 수 있다.
게시물 쓰면서 알게된 건데 그래프 안의 색이 진할수록
순수도가 높아지는 (gini 계수가 낮아지는)것을 표현하는 것 같다.

흥미롭..
그렇다면 나이, 성별 둘 다로 분할해보자.
나이, 성별 - 분할기준 확인
# 지니지수 -- 분할 기준 확인
train_temp_X = np.array(df_tree_t[['나이','성별']])
train_temp_y = np.array(df_tree_t['good/bad'])
train_temp_y = train_temp_y.reshape(-1,1)
# 지니지수의 의사결정트리 모델 피팅
gini_clf = tree.DecisionTreeClassifier(criterion = "gini", max_depth = 3,
random_state= 20 )
gini_clf = gini_clf.fit(train_temp_X, train_temp_y)
# 시각화
dot_data = tree.export_graphviz(gini_clf, # 의사결정나무 모델 대입
out_file = None, #file 로 변환할 것인가
feature_names = ['나이','성별'], #feature이름
class_names = ['good', 'bad'], #target 이름
filled = True, # 그림에 색상을 넣을 것인가)
rounded = True, # 반올림 할 것인가
special_characters = True) # 특수문자를 사용할 것인가
graph = gv.Source(dot_data)
graph
완전 순수한 게 보인다
정확도를 확인하고, 혼동행렬로 확인해보자.
# Fitting 된 모델로 x_valid 를 통해 예측을 진행
y_pred_gini = gini_clf.predict(train_temp_X)
y_pred_e = gini_clf.predict(train_temp_X)
print('Accuracy : %.2f'%accuracy_score(train_temp_y, y_pred_e))
print(confusion_matrix(train_temp_y,y_pred_e))Accuracy : 0.80
[[40 10]
[10 40]]
정확도 80%, 혼동행렬로 보았을 때 오류가 나지 않은 것이 80개이므로 나쁘지 않은 결과이다.
속성 중요도를 확인해보자.
# 속성 중요도 확인
feature_importance = pd.DataFrame(gini_clf.feature_importances_.reshape((1,-1)),
columns = [['나이','성별']],index = ['feature_importance'])
feature_importance
위에서 확인한 대로 성별이 훨씬 더 중요한 속성임을 알 수 있다.
엔트로피 기준
엔트로피일 때는 어떨까
엔트로피값이 높을수록 불순도가 높으며, 불순도가 클수록 자식 노드 내의 이질성이 큰 것을 의미한다.
Entopy 값이 낮은 것이 좋은 것이다.
나이기준
# 엔트로피 -- 나이기준
train_temp_X = np.array(df_tree_t['나이'])
train_temp_X = train_temp_X.reshape(-1,1)
train_temp_y = np.array(df_tree_t['good/bad'])
train_temp_y = train_temp_y.reshape(-1,1)
# 엔트로피의 의사결정트리 모델 피팅
entropy_clf = tree.DecisionTreeClassifier(criterion = "entropy", max_depth = 3,
random_state= 20 )
entropy_clf = entropy_clf.fit(train_temp_X, train_temp_y)
# 시각화
dot_data = tree.export_graphviz(gini_clf, # 의사결정나무 모델 대입
out_file = None, #file 로 변환할 것인가
feature_names = ['나이'], #feature이름
class_names = ['good', 'bad'], #target 이름
filled = True, # 그림에 색상을 넣을 것인가)
rounded = True, # 반올림 할 것인가
special_characters = True) # 특수문자를 사용할 것인가
graph = gv.Source(dot_data)
graph
영 별루다.
성별기준
# 엔트로피 -- 성별기준
train_temp_X = np.array(df_tree_t['성별'])
train_temp_X = train_temp_X.reshape(-1,1)
train_temp_y = np.array(df_tree_t['good/bad'])
train_temp_y = train_temp_y.reshape(-1,1)
# 지니지수의 의사결정트리 모델 피팅
entropy_clf = tree.DecisionTreeClassifier(criterion = "entropy", max_depth = 3,
random_state= 20 )
entropy_clf = entropy_clf.fit(train_temp_X, train_temp_y)
# 시각화
dot_data = tree.export_graphviz(gini_clf, # 의사결정나무 모델 대입
out_file = None, #file 로 변환할 것인가
feature_names = ['성별'], #feature이름
class_names = ['good', 'bad'], #target 이름
filled = True, # 그림에 색상을 넣을 것인가)
rounded = True, # 반올림 할 것인가
special_characters = True) # 특수문자를 사용할 것인가
graph = gv.Source(dot_data)
graph
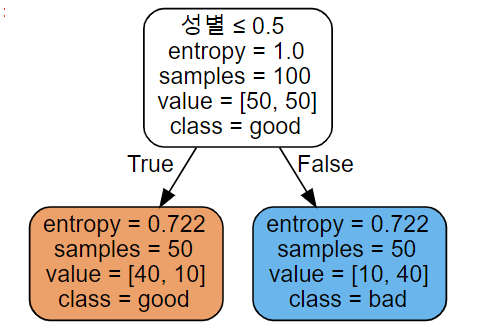
아까와 비슷한 결과이다.
# 엔트로피-- 분할 기준 확인
train_temp_X = np.array(df_tree_t[['나이','성별']])
train_temp_y = np.array(df_tree_t['good/bad'])
train_temp_y = train_temp_y.reshape(-1,1)
# 엔트로피의 의사결정트리 모델 피팅
entropy_clf = tree.DecisionTreeClassifier(criterion = "entropy", max_depth = 3,
random_state= 20 )
entropy_clf = entropy_clf.fit(train_temp_X, train_temp_y)
# 시각화
dot_data = tree.export_graphviz(gini_clf, # 의사결정나무 모델 대입
out_file = None, #file 로 변환할 것인가
feature_names = ['나이','성별'], #feature이름
class_names = ['good', 'bad'], #target 이름
filled = True, # 그림에 색상을 넣을 것인가)
rounded = True, # 반올림 할 것인가
special_characters = True) # 특수문자를 사용할 것인가
graph = gv.Source(dot_data)
graph
아까와 비슷한 결과가 나왔다.
정확도를 확인해보자.
from sklearn.metrics import accuracy_score
y_pred_e = entropy_clf.predict(train_temp_X)
print('Accuracy : %.2f' % accuracy_score(train_temp_y, y_pred_e))
from sklearn.metrics import confusion_matrix
confusion_matrix(train_temp_y,y_pred_e)
## 트리 분기 과정의 중요도 확인
input_impor = entropy_clf.feature_importances_.reshape((1,-1))
feature_importance = pd.DataFrame(input_impor, columns = [['나이','성별']],
index = ['feature_importance'])
feature_importance
정확도도 비슷하게 나왔다.
※ 해당 자료는 모두 공공 빅데이터 청년 인턴 교육자료들을 참고합니다.
'Data Science > Machine Learning' 카테고리의 다른 글
| [Python/ML] Mini Project - Water Quality Data (2) | 2022.08.17 |
|---|---|
| [Python/MachineLearning] Boston Housing Price Data 를 이용한 Decision Tree 실습 (2) | 2022.08.15 |
| [Python/ML] K-NN (K-Nearest Neigthbor , K-최근접이웃) (1) | 2022.08.06 |
| 데이터의 유사도(Similarity) 와 비유사도(Dis-Similarity, = 거리(Distance)) (1) | 2022.08.06 |
| [Python/Machine Learning] ML-Clustering (군집분석) : K-Means (4) | 2022.07.30 |



